A Tour of Machine Learning in Python¶
How to perform exploratory data analysis and build a machine learning pipeline.
In this tutorial I demonstrate key elements and design approaches that go into building a well-performing machine learning pipeline. The topics I'll cover include:
- Exploratory Data Analysis and Feature Engineering.
- Data Pre-Processing including cleaning and feature standardization.
- Dimensionality Reduction with Principal Component Analysis and Recursive Feature Elimination.
- Classifier Optimization via hyperparameter tuning and Validation Curves.
- Building a more powerful classifier through Ensemble Voting and Stacking.
Along the way we'll be using several important Python libraries, including scikit-learn and pandas, as well as seaborne for data visualization.
Our task is a binary classification problem inspired by Kaggle's "Getting Started" competition, Titanic: Machine Learning from Disaster. The goal is to accurately predict whether a passenger survived or perished during the Titanic's sinking, based on data such as passenger age, class, and sex. The training and test datasets are provided here.
I have chosen here to focus on the fundamentals that should be a part of every data scientist's toolkit. The topics covered should provide a solid foundation for launching into more advanced machine learning approaches, such as Deep Learning. For an intro to Deep Learning, see my notebook on building a Convolutional Neural Network with Google's TensorFlow API.
Contents¶
- 1.1 - Getting Started
- 1.1.a) - Importing the Data
- 1.1.b) - Data Completeness
- 1.1.c) - Thinking Up Front / Doing Your Homework!
- 1.1.d) - A Quick Glance at the Sorted CSV File
- 1.2 - Feature Engineering
- 1.2.a) - FamilySize, Surname, Title, and IsChild
- 1.2.b) - Grouping Families and Travellers
- 1.2.c) - Creating Bins for Age
- 1.2.d) - Logarithmic and 'Split' (Effective) Fare
- 1.3 - Univariate Feature Exploration
- 1.3.a) - Data Spread
- 1.3.b) - Univariate Plots
- 1.3.c) - The Role of Cabin
- 1.4 - Exploring Feature Relations
- 1.4.a) - Feature Correlations
- 1.4.b) - Typical Survivor Attributes
- 1.4.c) - Sex, Pclass, and IsChild
- 1.4.d) - FamilySize, Sex, and Pclass
- 1.4.e) - A Closer Look at PClass and Fare
- 1.4.f) - Survival vs Embarked, and its Relation to Pclass and Sex
- 1.4.g) - A Closer Look at GroupType and GroupSize
- 1.4.h) - The Impact of Age on Survival, Given Pclass and GroupSize
- 1.4.i) - Do Groups Tend to Survive or Perish Together?
- 1.5 - Summary of Key Findings
- 2.1 - Checking Data Consistency
- 2.1.a) - Title/Sex Inconsistencies
- 2.1.b) - Embarked/Fare Inconsistencies within Groups
- 2.1.c) - Age/Parch Inconsistencies
- 2.2 - Identifying Outliers
- 2.2.a) - Finding the Outliers
- 2.2.b) - What To Do With Our Outliers?
- 2.3 - Dealing with Missing Feature Entries
- 2.3.a) - Embarked and Fare
- 2.3.b) - Age
- 2.4 - Feature Normalization
- 2.4.a) - Converting Categorical Strings to Numbers
- 2.4.b) - Feature Scaling
3) Feature Selection and Dimensionality Reduction
- 3.1 - Getting Started
- 3.2 - Initial Performance on Full Feature Set
- 3.3 - Feature Importances of our Tree and Ensemble Classifiers
- 3.4 - Dimensionality Reduction via Recursive Feature Elimination (RFE)
- 3.5 - Dimensionality Reduction via Principal Component Analysis (PCA)
- 3.6 - Selecting a Feature Subset Based on our Exploratory Data Analysis
- 3.7 - Summary and Initial Comparison of Feature Subsets
Importing Python Libraries¶
# General Tools:
import math, os, sys # standard python libraries
import numpy as np
import pandas as pd # for dataframes
import itertools # combinatorics toolkit
import time # for obtaining computation execution times
from scipy import interp # interpolation function
# Data Pre-Processing:
from sklearn.preprocessing import StandardScaler # for standardizing data
from collections import Counter # object class for counting element occurences
# Machine Learning Classifiers:
from xgboost import XGBClassifier # xgboost classifier (http://xgboost.readthedocs.io/en/latest/model.html)
from sklearn.linear_model import LogisticRegression, SGDClassifier, Perceptron # linear classifiers
from sklearn.tree import DecisionTreeClassifier, ExtraTreeClassifier # decision tree classifiers
from sklearn.svm import SVC # support-vector machine classifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis # LDA classifier
from sklearn.ensemble import AdaBoostClassifier, BaggingClassifier, ExtraTreesClassifier, \
GradientBoostingClassifier, RandomForestClassifier, VotingClassifier
from sklearn.neighbors import KNeighborsClassifier # Nearest-Neighbors classifier
# Feature and Model Selection:
from sklearn.model_selection import StratifiedKFold # train/test splitting tool for cross-validation
from sklearn.model_selection import GridSearchCV # hyperparameter optimization tool via exhaustive search
from sklearn.model_selection import cross_val_score # automates cross-validated scoring
from sklearn.metrics import precision_score, recall_score, f1_score, roc_curve, auc # scoring metrics
from sklearn.feature_selection import RFE # recursive feature elimination
from sklearn.model_selection import learning_curve # learning-curve generation for bias-variance tradeoff
from sklearn.model_selection import validation_curve # for fine-tuning hyperparameters
from sklearn.pipeline import Pipeline
# Plotting:
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.graphics.mosaicplot import mosaic
# Manage Warnings:
import warnings
warnings.filterwarnings('ignore')
# Ensure Jupyter Notebook plots the figures in-line:
%matplotlib inline
1) Exploratory Data Analysis¶
1.1 - Getting Started¶
On April 15th 1912, the Titanic sank during her maiden voyage after colliding with an iceberg. Only 722 out of 2224 (32.5%) of its passengers and crew would survive. Such loss of life was in part due to the lack of sufficient numbers of lifeboats.
Though survival certainly involved an element of luck, some groups of people (e.g. women, children, the upper-class, etc.) may have been more likely to survive than others. Our goal is to use machine learning to predict which passengers survived the tragedy, based on factors such as gender, age, and social status.
For the Kaggle competition, we are to create a .csv submission file with two headers (PassengerId, Survived), and provide binary classification predictions for each passenger, where 1 = survived and 0 = deceased. The competition instructions and data are found here.

Data Dictionary¶
A few notes below about the meaning of the features in the raw dataset:
- Survival: 0 = False (Deceased), 1 = True (Survived).
- Pclass: Passenger ticket class; 1 = 1st (upper class), 2 = 2nd (middle class), 3 = 3rd (lower class).
- SibSp: Passenger's total number of siblings (including step-siblings) and spouses (legal) aboard the Titanic.
- Parch: Passenger's total number of parents or children (including stepchildren) aboard the Titanic.
- Embarked: Port of Embarkation, where C = Cherbourg, Q = Queenstown, S = Southampton.
- Age: Ages under 1 are given as fractions; if the age is estimated, it is in the form of xx.5.
a) Importing the Data¶
We will use Panda's dataframe structures for storing our data. As we explore our data and define new features, it will be useful to combine the training and test data into a single dataset.
df_train = pd.read_csv('./titanic-data/train.csv')
df_test = pd.read_csv('./titanic-data/test.csv')
dataset = pd.concat([df_train, df_test]) # combined dataset
test_Ids = df_test['PassengerId'] # identifiers for test set (besides survived=NaN)
df_train.head(5)
b) Data Completeness¶
Let us check upfront how complete our dataset is. Here we count the missing entries for each feature:
print('Training Set Dataframe Shape: ', df_train.shape)
print('Test Set Dataframe Shape: ', df_test.shape)
print('\nTotal number of entries in our dataset: ', dataset.shape[0])
print('\nNumber of missing entries in total dataset:')
print(dataset.isnull().sum())
Findings:
- Cabin data is missing for more than 75% of all passengers. This feature is too incomplete to include in our predictive models. However, we will still explore whether it offers any useful insights.
- We are missing about 20% of all age entries. We can attempt to impute or infer these missing entries based on average values or correlations with other features.
- We are missing two entries for Embarked, and one for Fare. We will impute these later.
c) Thinking Up Front / Doing Your Homework!¶
Gaining a bit more understanding of the problem context can provide several clues about the importance of variables, and help us make more sense of some of the relations that will be uncovered during our exploratory data analysis. So it's worth spending some time learning about what happened the night the Titanic sank (we can think of this as gaining some domain expertise). There are countless books, documentaries, and webpages dedicated to this subject. Here we highlight a few interesting facts:
- The Titanic's officers issued a "women and children first" order for evacuating passengers via lifeboats. However, there was no organized evacuation plan in place.
- There was in fact no general "abandon ship" order given by the captain, no public address system, and no lifeboat drill. Many passengers did not realize they were in any imminent danger, and some had to be goaded out of their cabins by members of the crew or staff.
- Lifeboats were segregated into different class sections, and there were more 1st-class passenger lifeboats than for the other two classes.
- We know it was more difficult for 3rd class passengers to access lifeboats, because the 3rd-class passenger sections were gated off from the 1st and 2nd-class areas of the ship. This was actually due to US immigration laws, which required immigrants (primarily 3rd-class) to be segregated and processed separately from other passengers upon arrival to the US. As a consequence, 3rd-class passengers had to navigate through a maze of staircases and corridors to reach the lifeboat deck.
Given these facts, we can already surmize that Sex, Pclass, and Age are likely to be the most important features. We will see what trends our Exploratory Data Analysis reveals.
Conerning the Fare feature: Fare is given in Pounds Sterling. There were really no 'standard' fares - many factors influenced the price charged, including the cabin size and number of people sharing a cabin, whether it was on the perimeter of the ship (i.e. with a porthole) or further inside, the qualities of the furnishings and provisions, etc. Children travelled at reduced rates, as did servants with 1st-class tickets. There seemed also to have been some family discount rates given, but we lack detailed information on how this was calculated. However, our research does tell us that:
- Ticket price (Fare) was cumulative, and included the cost for all passengers sharing that ticket.
d) A Quick Glance at the Sorted CSV File¶
Several useful observations can be made by quickly glancing at the CSV file containing the combined training and test data, and sorting some of the entries. Don't underestimate the usefulness of this rather rudimentary step!
Findings:
- Sort by Passenger Name: Passengers with matching surnames tend to also have matching entries for several other features: Pclass, Ticket, Fare, and Embarked (in addition to Cabin when available). This tells us we can use matching Ticket and Fare information as a basis for grouping families. If we sort by ticket, we can use surnames to distinguish between 'family' groups and non-related co-travellers.
- Sort by Age: All entries with the title 'Master' in the name correspond to males under the age of 15. This can be useful in helping us impute missing age data.
- Sort by Cabin: We find that Cabin number is available for most passengers with PClass=1, but generally missing for passengers of Pclass=2 or 3.
- Sort by Ticket Names: (I.Tickets not containing letters.) Tickets with 4-digits correspond to Pclass 2 or 3; the vast majority of 5-digit tickets correspond to Pclass 1 or 2; for 6-digit and 7-digit tickets, the leading number matches the Pclass. (II. Tickets including letters.) Tickets beginning with A/4 correspond to passengers with embarked=S and PClass=3. Tickets beginning with C.A. or CA also correspond to embarked=S, with PClass of 2 or 3. All tickets beginning with PC correspond to PClass=1. These patterns might be useful for helping us spot inconsistencies in the data.
1.2 - Feature Engineering¶
As we explore our data, we will likely think of new features that may help us understand or predict Survival. The definition of new features from the initial feature set is a dynamic process that typically occurs in the midst of feature exploration. However, for organizational purposes, as we add new features we will return here to group their definitions upfront.
a) FamilySize, Surname, Title, and IsChild¶
- It makes sense to sum Parch and SibSp together to create a new feature FamilySize.
- When identifying families, it will also be useful to compare surnames directly, so we split Name into Surname and Title. Our quick scan of the CSV file showed that all male children 15 and under have the title 'Master', hence Title may be useful for helping us estimate missing Age values.
- We also create a new variable, IsChild, to denote passengers aged 15 and under.
# Create a new column as a sum of listed relatives
dataset['FamilySize'] = dataset['Parch'] + dataset['SibSp'] + 1 # plus one to include the passenger
# Clean and sub-divide the name data into two new columns using Python's str.split() function.
# A look at the CSV contents shows that we should first split the string at ', ' to isolate
# the surname, and then split again at '. ' to isolate the title.
dataset['Surname'] = dataset['Name'].str.split(', ', expand=True)[0]
dataset['Title'] = dataset['Name'].str.split(', ', expand=True)[1].str.split('. ', expand=True)[0]
# Create a new feature identifying children (15 or younger)
dataset['IsChild'] = np.where(dataset['Age'] < 16, 1, 0)
# We can save this for handling or viewing with external software
# dataset.to_csv('./titanic-data/combined_newvars_v1.csv')
# Now let's print part of the dataframe to check our new variable definitions...
dataset[['Name', 'Surname', 'Title', 'SibSp', 'Parch', 'FamilySize', 'Age', 'IsChild']].head(10)
b) Grouping Families and Travellers¶
Sorting the data by Ticket, one finds that multiple passengers share the same ticket number. This can be used as a basis for grouping passengers that travelled together. It will also be useful to distinguish whether these passenger groups are immediate-related (1st-degree) families, entirely unrelated or non-immediate (e.g. friends, cousins), or a mix. We will also identify passengers who are travelling alone. We define:
- GroupID: an integer label uniquely identifying each group; a surrogate to Ticket.
- GroupSize: total number of passengers sharing a ticket.
- GroupType: categorization of group into 'Family', 'Non-Family', 'Mixed', 'IsAlone'.
- GroupNumSurvived: number of members in that group which are known to have survived.
- GroupNumPerished: number of members in that group which are known to have perished.
# Create mappings for assigning GroupID, GroupType, GroupSize, GroupNumSurvived,
# and GroupNumPerished
group_id = 1
ticket_to_group_id = {}
ticket_to_group_type = {}
ticket_to_group_size = {}
ticket_to_group_num_survived = {}
ticket_to_group_num_perished = {}
for (ticket, group) in dataset.groupby('Ticket'):
# Categorize group type (Family, Non-Family, Mixed, )
num_names = len(set(group['Surname'].values)) # number of unique names in this group
group_size = len(group['Surname'].values) # total size of this group
if group_size > 1:
if num_names == 1:
ticket_to_group_type[ticket] = 'Family'
elif num_names == group_size:
ticket_to_group_type[ticket] = 'NonFamily'
else:
ticket_to_group_type[ticket] = 'Mixed'
else:
ticket_to_group_type[ticket] = 'IsAlone'
# assign group size and grouop identifier
ticket_to_group_size[ticket] = group_size
ticket_to_group_id[ticket] = group_id
ticket_to_group_num_survived[ticket] = group[group['Survived'] == 1]['Survived'].count()
ticket_to_group_num_perished[ticket] = group[group['Survived'] == 0]['Survived'].count()
group_id += 1
# Apply the mappings we've just defined to create the GroupID and GroupType variables
dataset['GroupID'] = dataset['Ticket'].map(ticket_to_group_id)
dataset['GroupSize'] = dataset['Ticket'].map(ticket_to_group_size)
dataset['GroupType'] = dataset['Ticket'].map(ticket_to_group_type)
dataset['GroupNumSurvived'] = dataset['Ticket'].map(ticket_to_group_num_survived)
dataset['GroupNumPerished'] = dataset['Ticket'].map(ticket_to_group_num_perished)
# Let's print the first 4 group entries to check that our grouping was successful
counter = 1
break_point = 4
feature_list = ['Surname', 'FamilySize','Ticket','GroupID','GroupType', 'GroupSize']
print('Printing Sample Data Entries to Verify Grouping:\n')
for (ticket, group) in dataset.groupby('Ticket'):
print('\n', group[feature_list])
if counter == break_point:
break
counter += 1
# Let's also check that GroupNumSurvived and GroupNumPerished were created accurately
feature_list = ['GroupID', 'GroupSize', 'Survived','GroupNumSurvived', 'GroupNumPerished']
dataset[feature_list].sort_values(by=['GroupID']).head(15)
Checking For Inconsistencies¶
# Check for cases where FamilySize = 1 but GroupType = Family
data_reduced = dataset[dataset['FamilySize'] == 1]
data_reduced = data_reduced[data_reduced['GroupType'] == 'Family']
# nri = 'NumRelatives inconsistency'
nri_passenger_ids = data_reduced['PassengerId'].values
nri_unique_surnames = set(data_reduced['Surname'].values)
# How many occurrences?
print('Number of nri Passengers: ', len(nri_passenger_ids))
print('Number of Unique nri Surnames: ',len(nri_unique_surnames))
# We will find that there are only 7 occurences, so let's go ahead and view them here:
data_reduced = data_reduced.sort_values('Name')
data_reduced[['Name', 'Ticket', 'Fare','Pclass', 'Parch',
'SibSp', 'GroupID', 'GroupSize','GroupType']].head(int(len(nri_passenger_ids)))
- With the exception of Mrs. John James Ware, we see that each of these passengers is paired with another having the same surname; we can presume that these are 2nd-degree relations (such as cousins), hence why each still has FamilySize=1 (which refers only to immediate family).
#Check for cases where FamilySize > 1 but GroupType = NonFamily
data_reduced = dataset[dataset['FamilySize'] > 1]
data_reduced = data_reduced[data_reduced['GroupType'] == 'NonFamily']
# ngwr = 'not grouped with relatives'
ngwr_passenger_ids = data_reduced['PassengerId'].values
ngwr_unique_surnames = set(data_reduced['Surname'].values)
# How many occurences?
print('Number of ngwr Passengers: ', len(ngwr_passenger_ids))
print('Number of Unique ngwr Surnames: ',len(ngwr_unique_surnames))
feature_list = ['PassengerId', 'Name', 'Ticket', 'Fare','Pclass', 'Parch',
'SibSp', 'GroupID', 'GroupSize','GroupType']
data_reduced[feature_list].sort_values('GroupID').head(int(len(ngwr_unique_surnames)))
If we look at matching group IDs, then in some cases these inconsistencies may be due to passenger substitutions. However, we need to better understand the significance of the names in parenthesis.
Consider GroupID=628: we have "Miss Elizabith Eustis" and "Mrs. Walter Sephenson (Martha Eustis)". A quick check of geneology databases online reports that there was indeed a miss Mrs. Walter Bertram Stephenson that boarded the Titanic; in this case, Martha Eustis is her maiden name, while Mrs. Walter B. Stephenson gives her title in terms of her husband's name (an old-fashioned practice). Another example is for GroupID=77, where we have "Brown, Mrs. John Murray (Caroline Lane Lamson)" and "Appleton, Mrs. Edward Dale (Charlotte Lamson)", another case of two related passengers whose names are given in terms of those of their husbands.
Since this hunt for inconsistencies turned up only 17 entries, we can manually correct the Group Type in cases (such as these two examples) where it is obvious the passengers are indeed family.
# manually correcting some mislabeled group types
# note: if group size is greater than the number of listed names above, we assign to Mixed
passenger_ids_toFamily = [167, 357, 572, 1248, 926, 1014, 260, 881, 592, 497]
passenger_ids_toMixed = [880, 1042, 276, 766]
dataset['GroupType'][dataset['PassengerId'].isin(passenger_ids_toFamily)] = 'Family'
dataset['GroupType'][dataset['PassengerId'].isin(passenger_ids_toMixed)] = 'Mixed'
## for verification:
# feature_list = ['PassengerId', 'Name', 'GroupID', 'GroupSize','GroupType']
# dataset[feature_list][dataset['PassengerId'].isin(
# passenger_ids_toFamily)].sort_values('GroupID').head(len(passenger_ids_toFamily))
LargeGroup Feature:
Lastly, we'll define a new feature, called LargeGroup, which equals 1 for GroupSize of 5 and up, and is 0 otherwise. For an explanation of what motivated this new feature, see our "Summary of Key Findings".
dataset['LargeGroup'] = np.where(dataset['GroupSize'] > 4, 1, 0)
c) Creating Bins for Age¶
During feature selection, we will assess whether this is advantageous over the continuous-variable representation.
# creation of Age bins; see Section 1.3-b
bin_thresholds = [0, 15, 30, 40, 59, 90]
bin_labels = ['0-15', '16-29', '30-40', '41-59', '60+']
dataset['AgeBin'] = pd.cut(dataset['Age'], bins=bin_thresholds, labels=bin_labels)
d) Logarithmic and 'Split' (Effective) Fare¶
Our research found that ticket price was cumulative based on the number of passengers sharing that ticket. We therefore define a new fare variable, 'SplitFare', that subdivides the ticket price based on the number of passengers sharing that ticket. We also create 'log10Fare' and 'log10SplitFare' to map these to a base-ten logarithmic scale.
# split the fare based on GroupSize; express as fare-per-passenger on a shared ticket
dataset['SplitFare'] = dataset.apply(lambda row: row['Fare']/row['GroupSize'], axis=1)
# Verify new feature definition
features_list = ['GroupSize', 'Fare', 'SplitFare']
dataset[features_list].head()
# Map to log10 scale
dataset['log10Fare'] = np.log10(dataset['Fare'].values + 1)
dataset['log10SplitFare'] = np.log10(dataset['SplitFare'].values + 1)
1.3 - Univariate Feature Exploration¶
a) Data Spread¶
We can use pandas' built-in methods to get a quick first impression of how our ordinal data are distributed:
dataset.describe()
Findings:
- Most of our passengers travelled without any relatives onboard. Less than 50% had FamilySize > 1.
- Less than 9% of our passengers were children.
- While most fares were under 15.00, it would appear there are passengers on board whose fare price (e.g. 512.00) are more than five standard deviations above this, implying a significant spread in passenger wealth. We will need to examine the Fare feature for outliers.
- Only 38.8% of the passengers in our training set survived. This gives us a baseline: if we simply predicted Survival=0 for all passengers, we could expect to achieve roughly 60% accuracy. Obviously we will aim to do much better than this using our machine learning models.
b) Univariate Plots¶
Let's begin by looking at how mean survival depends on individual feature values:
def barplots(dataframe, features, cols=2, width=10, height=10, hspace=0.5, wspace=0.25):
# define style and layout
sns.set(font_scale=1.5)
plt.style.use('seaborn-whitegrid')
fig = plt.figure(figsize=(width, height))
fig.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=wspace, hspace=hspace)
rows = math.ceil(float(dataframe.shape[1]) / cols)
# define subplots
for i, column in enumerate(dataframe[features].columns):
ax = fig.add_subplot(rows, cols, i + 1)
sns.barplot(column,'Survived', data=dataframe)
plt.xticks(rotation=0)
plt.xlabel(column, weight='bold')
feature_list = ['Sex','Pclass', 'Embarked', 'SibSp', 'Parch', 'FamilySize']
barplots(dataset, features=feature_list, cols=3, width=15, height=40, hspace=0.35, wspace=0.4)

We'll also consider the statistics associated with GroupType and GroupSize, which we defined in Section 1.2 (Feature Engineering) while grouping families and co-travellers with shared tickets:
feature_list = ['GroupType','GroupSize']
barplots(dataset, features=feature_list, cols=2, width=15, height=75, hspace=0.3, wspace=0.3)

Note that the black 'error bars' on our plots represent 95% confidence intervals. For practical purposes, when comparing survival versus feature values, these bars can be thought of as statistical uncertainties given our limited sample size and the spread in the data.
Findings:
- Sex and Pclass both show a strong statistically significant influence on survival.
- FamilySize of 2-4 is more advantageous than larger families or passengers without family. Survival drops sharply at FamilySize=5 and beyond.
- Embarked shows no clear trend; we will later investigate this feature in more detail.
- For GroupType, we can clearly see that lone passengers have a lower survival probability compared to other groups (note, this also mirrors what we see for FamilySize=1 and GroupSize=1). Between the other three categories of Family, NonFamily, and Mixed, the wide confidence bounds on the latter two make it difficult to assert whether any of these three have a statistically significant advantage relative to each other.
- For GroupSize, we see a trend similar to the one we observed for FamilySize, where survival increases up to GroupSize=4, and then drops off sharply for group sizes of 5 and above. However, compared to FamilySize, the confidence bounds for this variable are tighter, and the relation between survival and GroupSize up to 4 appears more linear, suggesting that GroupSize may be a better variable for model training than FamilySize.
Given the FamilySize feature, it is not clear whether SibSp and Parch are now gratuitous, or whether they can still offer some valuable insight. This will need further investigation.
Now let's examine Age and Fare:
def histograms(dataframe, features, force_bins=False, cols=2, width=10, height=10, hspace=0.2, wspace=0.25):
# define style and layout
sns.set(font_scale=1.5)
plt.style.use('seaborn-whitegrid')
fig = plt.figure(figsize=(width, height))
fig.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=wspace, hspace=hspace)
rows = math.ceil(float(dataframe.shape[1]) / cols)
# define subplots
for i, column in enumerate(dataframe[features].columns):
ax = fig.add_subplot(rows, cols, i + 1)
df_survived = dataframe[dataframe['Survived'] == 1]
df_perished = dataframe[dataframe['Survived'] == 0]
if force_bins is False:
sns.distplot(df_survived[column].dropna().values, kde=False, color='blue')
sns.distplot(df_perished[column].dropna().values, kde=False, color='red')
else:
sns.distplot(df_survived[column].dropna().values, bins=force_bins[i], kde=False, color='blue')
sns.distplot(df_perished[column].dropna().values, bins=force_bins[i], kde=False, color='red')
plt.xticks(rotation=25)
plt.xlabel(column, weight='bold')
feature_list = ['Age', 'Fare']
bins = [range(0, 81, 1), range(0, 300, 2)]
histograms(dataset, features=feature_list, force_bins=bins, cols=2, width=15, height=70, hspace=0.3, wspace=0.2)

Blue denotes survivors; red denotes those who perished.
Findings:
- Age: Survival improves for children. Age-dependent differences in survival are perhaps easier to see in a kernel density estimate (KDE) plot (see below). Elderly passengers, around age 60 and up, tended to perish.
- Fare: Unsurpisingly passengers with the lowest fares perished in greater numbers. Fare values are indeed widely spread; we see many passengers with fares exceeding 50.00 and 100.00. It may be sensible to convert fare into a logarithmic value to explore its relation to survival.
Below we generate KDE plots and convert Fare to a base-10 log scale. We will also examine the 'SplitFare' variable, which divides the total ticket Fare price among the number of passengers sharing that ticket:
def univariate_kdeplots(dataframe, plot_features, cols=2, width=10, height=10, hspace=0.2, wspace=0.25):
# define style and layout
sns.set(font_scale=1.5)
plt.style.use('seaborn-whitegrid')
fig = plt.figure(figsize=(width, height))
fig.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=wspace, hspace=hspace)
rows = math.ceil(float(dataframe.shape[1]) / cols)
# define subplots
for i, feature in enumerate(plot_features):
ax = fig.add_subplot(rows, cols, i + 1)
g = sns.kdeplot(dataframe[plot_features[i]][(dataframe['Survived'] == 0)].dropna(), shade=True, color="red")
g = sns.kdeplot(dataframe[plot_features[i]][(dataframe['Survived'] == 1)].dropna(), shade=True, color="blue")
g.set(xlim=(0 , dataframe[plot_features[i]].max()))
g.legend(['Perished', 'Survived'])
plt.xticks(rotation=25)
ax.set_xlabel(plot_features[i], weight='bold')
feature_list = ['Age', 'log10Fare', 'log10SplitFare']
univariate_kdeplots(dataset, feature_list, cols=1, width=15, height=100, hspace=0.4, wspace=0.25)

We can more clearly see:
- Children have a survival advantage, particularly those 13 and under.
- Elderly passengers ~60 and up are most likely to perish.
- Survival is poorest for Fares of 10.0 or less ($\lt$ 1.0 on this log scale).
- The Fare KDE plot shows 2 clear points of concavity near log(Fare)=0.9 and log(Fare)=1.4, and possibly a third near log(Fare)=1.8. For Splitfare, the variance on the peaks appear smaller, and there seem to be 3 main peaks, possibly corresponding to the means for Pclasses 3, 2 and 1. It should be investigated how Fare and SplitFare is distributed among different Pclasses.
- We note that there appear several passengers whose Fare is listed as 0.0, virtually all of whom perished.
Let's now consider discretized Age Bins and see if this makes any of the Age-related trends clearer. First we'll group age into bins of 5 years:
dataset['AgeBin_v1'] = pd.cut(dataset['Age'], bins=range(0, 90, 5))
sns.set(rc={'figure.figsize':(14,8.27)})
sns.set(font_scale=1.0)
plt.style.use('seaborn-whitegrid')
g = sns.barplot('AgeBin_v1','Survived', data=dataset)
table = pd.crosstab(dataset['AgeBin_v1'], dataset['Survived'])
print('\n', table)

Findings (complementary to KDE plot):
- Survival tends to be highest in the 0-15 age group.
- There is a slight increase in survival between 30-40 relative to adjacent bins.
- Survival generally decreases after age 60; however, we have fewer samples upon which to base our statistics.
- However, due to the large variances on all bars, these findings need to be taken with some caution.
Let's use these trends to custom-define a new set of bins with reduced granulation (see Section 1.2-a for the 'AgeBin' variable definition):
sns.set(font_scale=1.5)
plt.style.use('seaborn-whitegrid')
g = sns.barplot('AgeBin','Survived', data=dataset)

This makes it even clearer that being a child (0-15) is a statistically significant predictor of higher survival. Let's focus on our 'IsChild' variable, which equals 1 for Ages 15 and under, otherwise 0.
barplots(dataset, features=['IsChild'], cols=1, width=5, height=100, hspace=0.3, wspace=0.2)

Findings:
- Children do indeed have significantly higher survival than non-children, as we might expect from the "women and children first" evacuation order. However, the survival probability (60%) is still quite a bit lower than that of Sex='female' (~73%) and Pclass=1 (~62.5%). There are clearly other features that play an important role in the likelihood of a child surviving, which we'll explore in Section 1.4.
What about discretizing log10 Fare into bins? We do this below.
sns.set(rc={'figure.figsize':(14,8.27)})
sns.set(font_scale=1.5)
plt.style.use('seaborn-whitegrid')
dataset['FareBin'] = pd.cut(dataset['log10Fare'], bins=5)
g = sns.barplot('FareBin','Survived', data=dataset)

Findings:
- There is an approximately linear increase in survival probability with increasing FareBin. Could this in fact provide better predictive granularization than Pclass? We can test this idea later during Feature Selection.
Does this trend hold true if we look at the log10 SplitFare variable?
sns.set(font_scale=1.0)
plt.style.use('seaborn-whitegrid')
dataset['SplitFareBin'] = pd.cut(dataset['log10SplitFare'], bins=5)
g = sns.barplot('SplitFareBin','Survived', data=dataset)

Unfortunately the nice linear trend doesn't quite hold up. Bins 2-3 are nearly identical; similarly for bins 4-5. This looks more like a replication of the Pclass dependencies. What if we plot again with more bins?
sns.set(font_scale=1.0)
plt.style.use('seaborn-whitegrid')
dataset['SplitFareBin'] = pd.cut(dataset['log10SplitFare'], bins=10)
g = sns.barplot('SplitFareBin','Survived', data=dataset)

The linearity is somewhat better but not great, and we also have relatively low confidences for our highest two bins.
c) The Role of Cabin¶
Can information about passenger Cabin be useful for predicting survival? Initially, one might think that passengers in cabins located more deeply within the Titanic are more likely to perish. The cabins listed in our passenger data are prefixed with the letters A through G. Some background research tells us that this letter corresponds to the deck on which the cabin was located (with A being closer to the top, G being deeper down). There also appears to be a single cabin entry beginning with the letter 'T', but it's not clear what this means, so we will omit it.
Let's take a look at whether the deck the cabin was located on had any significant influence on survival:
dataset['CabinDeck'] = dataset.apply(lambda row:
str(row['Cabin'])[0] if str(row['Cabin'])[0] != 'n'
else row['Cabin'], axis=1)
sns.set(font_scale=1.5)
plt.style.use('seaborn-whitegrid')
g = sns.barplot('CabinDeck','Survived', data=dataset[dataset['CabinDeck'] != 'T'].sort_values('CabinDeck'))

Findings:
- CabinDeck appears to have no significant influence on survival.
A few other comments:
- The cabin data we have exists predominantly for members of Pclass=1; it is missing for nearly all other passengers.
- We know that gates in some of the stairwells leading to higher decks were left shut, due to the segregation of 3rd-class passengers from the rest. This of course mainly impacted survival in Pclass=3.
- The iceberg penetrated the Titanic below deck G. Hence, there wasn't any localized damage/flooding directly to any of the cabins we are considering.
- Lower-class passengers were not necessarily on lower decks than higher-class passengers. The following schematic of passenger class cabin distributions shows that most decks contained a mix of classes, albeit 3rd-class passengers tended to be far towards the rear or front of the ship:
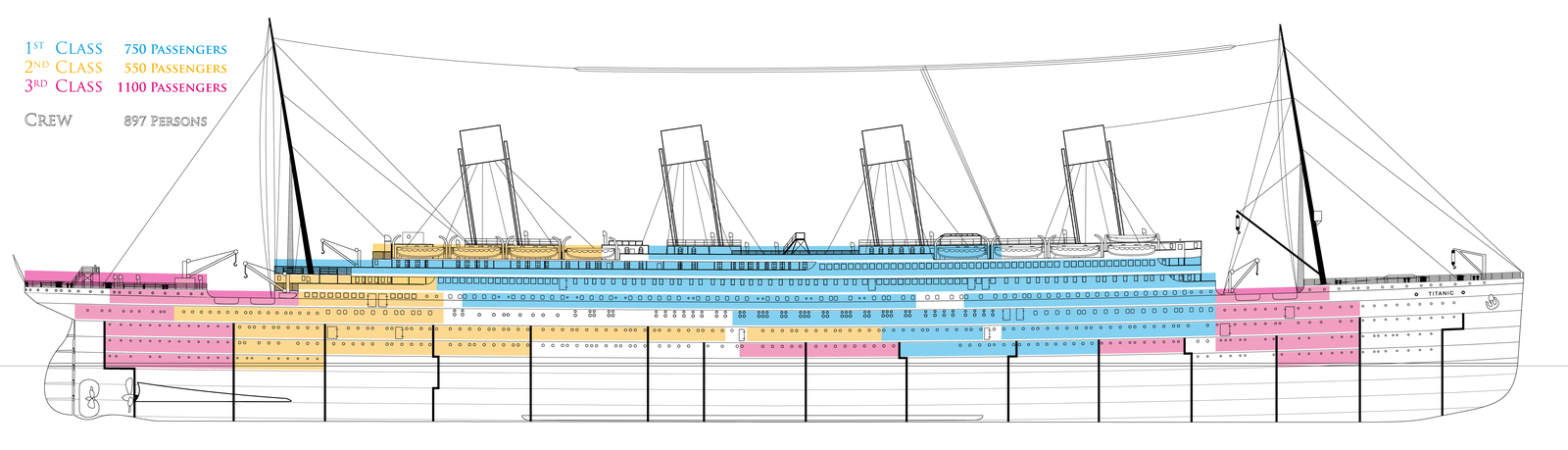
Conclusion:
- Cabin is not a useful feature for survival prediction. Having a known cabin number basically just tells us that the passenger is Pclass=1, and is therefore redundant.
1.4 - Exploring Feature Relations¶
We now proceed with a multivariate analysis to explore how different features influence each other's impact on passenger survival.
a) Feature Correlations¶
Let's first look at correlations between survival and some of our existing numerical features:
feature_list = ['Survived', 'Pclass', 'Fare', 'SplitFare', 'Age', 'SibSp', 'Parch', 'FamilySize', 'GroupSize']
plt.figure(figsize=(18,14))
sns.set(font_scale=1.5)
g = sns.heatmap(dataset[np.isfinite(dataset['Survived'])][feature_list].corr(),
square=True, annot=True, cmap='coolwarm', fmt='.2f')

Findings:
- Pclass and SplitFare both show significant correlation with survival, unsurprisingly.
- There is some negative correlation between Age and FamilySize. This makes sense, as we might expect larger families to consist of more children, thereby lowering the mean age.
- There is some negative correlation between Age and Pclass. This suggests that upper-class passengers (PClass=1) are generally older than lower-class ones.
- Unsurprisingly Sibsp, Parch, and FamilySize are all strongly correlated with each other.
- GroupSize appears to correlate positively with Fare, but has near-zero correlation with SplitFare, further indicative that Fare is cumulative and represents the total paid for all passengers sharing a ticket.
In our univariate plots we saw that FamilySize had a clear impact on survival, yet here the correlations between Survival and FamilySize are near-zero. This may be explained by the fact that the positive trend between survival and FamilySize reverses into a negative trend after FamilySize=4. A similar reason may be behind the fact that Survival shows little correlation with Age, yet we know Age < 15 (i.e. child) is an advantage.
At this point it is also common to examine 'pair plots' of variables. However, given that most of our features span only a few discrete values, this turns out to be of limited informative value for us, and is hence omitted.
b) Typical Survivor Attributes¶
We can easily check which combinations of nominal features give the best and worst survival probabilities. However, this is limited by small sample size for some of our feature combination subsets. Nonetheless it can be useful for benchmarking purposes. We limit this quick exercise to only a few features (if we specify too many, our sample sizes for each combination become too small).
def get_mostProbable(data, feature_list, feature_values):
high_val, low_val = 0, 1
high_set, low_set = [], []
high_size, low_size = [], []
for combo in itertools.product(*feature_values):
subset = dataset[dataset[feature_list[0]] == combo[0]]
for i in range(len(feature_list))[1:]:
subset = subset[subset[feature_list[i]] == combo[i]]
mean_survived = subset['Survived'].mean()
if mean_survived > high_val:
high_set = combo
high_val = mean_survived
high_size = subset.shape[0]
if mean_survived < low_val:
low_set = combo
low_val = mean_survived
low_size = subset.shape[0]
print('\n*** Most likely to survive ***')
for i in range(len(feature_list)):
print('%s : %s' % (feature_list[i], high_set[i]))
print('... with survival probability %.2f' % high_val)
print('and total set size %s' % high_size)
print('\n*** Most likely to perish ***')
for i in range(len(feature_list)):
print('%s : %s' % (feature_list[i], low_set[i]))
print('... with survival probability %.2f' % low_val)
print('and total set size %s' % low_size)
An examination of the best and worst combinations of 'Sex' and 'Pclass':
feature_list = ['Pclass', 'Sex']
feature_values = [[1, 2, 3], ['male', 'female']] # ['Pclass', 'Sex']
get_mostProbable(dataset, feature_list, feature_values)
Findings:
- Virtually all 1st-class females survived (97%).
- 3rd-class males where the most likely to perish, with only 14% survival.
This isn't too surprising, although the associated survival probabilities are useful to note.
What if we also consider whether the passenger was a child?
feature_list = ['Pclass', 'Sex', 'IsChild']
feature_values = [[1, 2, 3], ['male', 'female'], [0, 1]] # ['Pclass', 'Sex', 'IsChild']
get_mostProbable(dataset, feature_list, feature_values)
Findings:
- Male rather than female first-class children are most likely to survive (but note that we have only 5 samples in this subset).
- Males in Pclass=2 seem to fare worse than Pclass=3 when we delineate between adults and children.
c) Sex, Pclass, and IsChild¶
Let's take a closer look at how survival differs between male and female across all three passenger classes:
plt.figure(figsize=(10,5))
plt.style.use('seaborn-whitegrid')
g = sns.barplot(x="Pclass", y="Survived", hue="Sex", data=dataset)

Findings:
- Males in Pclass 2 and 3 have almost the same survival probability. Survival roughly doubles when going to Pclass 1.
- Females in Pclass 2 are almost as likely to survive as those in Pclass 1; however, survival drops sharply (by ~40%) for Pclass 3.
Now let's see how this subdivides between children and adults:
subset = dataset[dataset['IsChild'] == 0]
table = pd.crosstab(subset[subset['Sex']=='male']['Survived'], subset[subset['Sex']=='male']['Pclass'])
print('\n*** i) Adult Male Survival ***')
print(table)
table = pd.crosstab(subset[subset['Sex']=='female']['Survived'], subset[subset['Sex']=='female']['Pclass'])
print('\n*** ii) Adult Female Survival ***')
print(table)
subset = dataset[dataset['IsChild'] == 1]
table = pd.crosstab(subset[subset['Sex']=='male']['Survived'], subset[subset['Sex']=='male']['Pclass'])
print('\n*** iii) Male Child Survival ***')
print(table)
table = pd.crosstab(subset[subset['Sex']=='female']['Survived'], subset[subset['Sex']=='female']['Pclass'])
print('\n*** iv) Female Child Survival ***')
print(table)
g = sns.factorplot(x="IsChild", y="Survived", hue="Sex", col="Pclass", data=dataset, ci=95.0)
# ci = confidence interval (set to 95%)

Findings:
Males:
- Virtually all of the male children in our training dataset survive in Pclasses 1 and 2.
- The IsChild feature clearly has a significant impact on survival likelihood (well above 50%) for Pclass 1 and 2; for Pclass 3, this difference is a more modest 20%.
Females:
- All but one of the Pclass 1 and 2 female children survived.
- Survival of a female child versus an adult is only modestly better (by perhaps 5%).
- The vast majority of female passengers who perished were in Pclass=3 (see table ii).
d) FamilySize, Sex, and Pclass¶
We saw earlier that FamilySize improves survival up to FamilySize=4, then sharply drops. Does Sex have any influence on this trend?
g = sns.factorplot(x="FamilySize", y="Survived", hue="Sex", data=dataset, ci=95.0)
# ci = confidence interval (set to 95%)
plt.style.use('seaborn-whitegrid')

Findings:
- Increase in Survival with FamilySize (up to 4) is greater for males than females.
- Both sexes follow the same general trend otherwise.
It would be interesting to know the role Pclass plays in FamilySize survival:
# Class distribution for a given FamilySize
table = pd.crosstab(dataset['FamilySize'], dataset['Pclass'])
print('\n', table)
table_fractions = table.div(table.sum(1).astype(float), axis=0)
g = table_fractions.plot(kind="bar", stacked=True)
plt.xticks(rotation=0)
plt.xlabel('FamilySize', weight='bold')
plt.ylabel('Fraction of Total')
plt.tight_layout()
leg = plt.legend(title='Pclass', loc=9, bbox_to_anchor=(1.05, 1.0))
# Comparison of surival
g = sns.factorplot(x="FamilySize", y="Survived", hue="Pclass", data=dataset, ci=95.0)


Findings:
- FamilySize > 5 were predominantly 3rd class.
- FamilySize = 4 was predominantly 1st and 2nd class.
- Pclass 1 breaks from the linear trend early, dipping below Pclass=2 for FamilySize=4.
Finally, let's look at how the various FamilySizes are split between the two sexes:
# Sex distribution for a given FamilySize
table = pd.crosstab(dataset['FamilySize'], dataset['Sex'])
print('\n', table)
table_fractions = table.div(table.sum(1).astype(float), axis=0)
g = table_fractions.plot(kind="bar", stacked=True)
plt.xticks(rotation=0)
plt.xlabel('FamilySize', weight='bold')
plt.ylabel('Fraction of Total')
plt.tight_layout()
leg = plt.legend(title='Sex', loc=9, bbox_to_anchor=(1.05, 1.0))

Findings:
- The proportion of males is greatest for FamilySize=1, and begins to drop for FamilySizes of 2, 3, and 4. Hence, the trend we observed earlier of FamilySizes 2, 3 and 4 becoming increasingly advantageous to survival might in part be driven by the Sex feature.
- For FamilySize > 4, we cannot associate the lower survival rates to a higher proportion of males, as the sexes are mixed and slightly in favour of females.
e) A Closer Look at PClass and Fare¶
We know that fare and Pclass are strongly correlated, and that Pclass on its own is a strong predictor of survival. Our main question is: can the distribution of Fares within each Pclass offer better granulization about survival?
First let's examine how the fares are distributed:
sns.set(font_scale=1.5)
plt.style.use('seaborn-whitegrid')
fig = plt.figure(figsize=(14, 5))
fig.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=0.3, hspace=0.5)
ax = fig.add_subplot(1, 2, 1)
ax = sns.boxplot(x="Pclass", y="Fare", hue="Survived", data=dataset)
ax.set_yscale('log')
ax = fig.add_subplot(1, 2, 2)
ax = sns.boxplot(x="Pclass", y="SplitFare", hue="Survived", data=dataset)
ax.set_yscale('log')

Findings:
- SplitFare provides less variance and better separation between Pclasses.
let's also examine Fare and SplitFare price versus GroupSize within each Pclass:
# Plots for Fare
sns.set(font_scale=1.5)
plt.style.use('seaborn-whitegrid')
fig = plt.figure(figsize=(14, 3))
fig.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=0.35, hspace=0.5)
for i, Pclass_ in enumerate([1, 2, 3]):
ax = fig.add_subplot(1, 3, i + 1)
ax = sns.pointplot(x='GroupSize', y='Fare', data=dataset[dataset['Pclass'] == Pclass_])
plt.title('Pclass = %s' % Pclass_)

# Plots for SplitFare
sns.set(font_scale=1.5)
plt.style.use('seaborn-whitegrid')
fig = plt.figure(figsize=(14, 3))
fig.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=0.35, hspace=0.5)
for i, Pclass_ in enumerate([1, 2, 3]):
ax = fig.add_subplot(1, 3, i + 1)
ax = sns.pointplot(x='GroupSize', y='SplitFare', data=dataset[dataset['Pclass'] == Pclass_])
plt.title('Pclass = %s' % Pclass_)

Findings:
- Fare scales positively with Groupsize, whereas in SplitFare this positive trend disappears. (As we might expect, since the impact of GroupSize on Fare has been normalized out for SplitFare.)
- In SplitFare for Pclass=3, there appears to be a decreasing trend up to GroupSize=4. It is possible this is due partially to fare discounts applied to families in that passenger class.
def KDE_feature_vs_Pclass(dataframe, feature,
width=10, height=10, hspace=0.2, wspace=0.25):
# define style and layout
cols=3
sns.set(font_scale=1.5)
plt.style.use('seaborn-whitegrid')
fig = plt.figure(figsize=(width, height))
fig.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=wspace, hspace=hspace)
rows = math.ceil(float(dataframe.shape[1]) / cols)
# define subplots
for i, pclass in enumerate(['Pclass1', 'Pclass2', 'Pclass3']):
ax = fig.add_subplot(rows, cols, i + 1)
df_subset = dataframe[dataframe['Pclass'] == i+1]
g = sns.kdeplot(df_subset[feature][df_subset['Survived'] == 0].dropna(), shade=True, color="red")
g = sns.kdeplot(df_subset[feature][(df_subset['Survived'] == 1)].dropna(), shade=True, color="blue")
g.set(xlim=(df_subset[feature].min() , df_subset[feature].max()))
g.legend(['Perished', 'Survived'])
plt.xticks(rotation=25)
plt.title(pclass)
ax.set_xlabel(feature, weight='bold')
KDE_feature_vs_Pclass(dataset, 'log10Fare', width=20, height=50, hspace=0.2, wspace=0.25)
KDE_feature_vs_Pclass(dataset, 'log10SplitFare', width=20, height=50, hspace=0.2, wspace=0.25)


Findings:
- Fare does appear to be a good predictor of survival within each Pclass, suggesting it provides better granulation than Pclass alone.
- For SplitFare, on the other hand, higher fares within each Pclass no longer appear to yield higher survival. In fact, for Pclass 2 and 3, we see the opposite. Why? Consider the higher survival at the lower values of SplitFare. This could be attributable to the fact that GroupSizes 2-4, which we found earlier to have higher survival rates, generally tended to have lower values of SplitFare, possibly due to family fare discounts.
These findings imply that any predictive value Fare has is derived predominantly from GroupSize. The amount of redundancy between Fare, Pclass, and GroupSize will be better elucidated through the dimensionality reduction techniques applied in Section 2.
f) Survival vs Embarked, and its Relation to Pclass and Sex¶
Recall from our univariate plots that passengers embarking at Cherbourg appeared to have a higher survival probability than those embarking at the other two ports. Let's investigate this in greater detail. First let's examine the Pclass distributions of passengers at each port.
table = pd.crosstab(dataset['Embarked'], dataset['Pclass'])
print(table)
table_fractions = table.div(table.sum(1).astype(float), axis=0)
g = table_fractions.reindex(['S', 'C', 'Q']).plot(kind="bar", stacked=True)
plt.xlabel('Embarked')
plt.ylabel('Fraction of Total')
plt.tight_layout()
leg = plt.legend(title='Pclass', loc=9, bbox_to_anchor=(1.1, 1.0))

Findings:
- Unsurprisingly, Cherbourg had the largest proprotion of Pclass=1 passengers.
- Interestingly, univariate survival probability for S and Q were roughly equal, yet we see here that S had a significantly larger fraction of passengers that were Pclass 1 and 2. Let's explore this in more detail by looking at Pclass survival rates for each embarkment port.
plt.figure(figsize=(10,5))
g = sns.barplot(x="Embarked", y="Survived", hue="Pclass", data=dataset)

We see that survial of passengers in PClass 3 was higher in both C and Q than it was in S. Could this be due to differences in the fraction of male/female passengers?
data_subset = dataset[dataset['Pclass']==3]
table = pd.crosstab(data_subset['Embarked'], data_subset['Sex'])
print('\n', table)
table_fractions = table.div(table.sum(1).astype(float), axis=0)
g = table_fractions.reindex(['S', 'C', 'Q']).plot(kind="bar", stacked=True)
plt.xlabel('Embarked')
plt.ylabel('Fraction of Total')
plt.title('Sex of Passengers in Pclass=3')
plt.tight_layout()
leg = plt.legend(title='Sex', loc=9, bbox_to_anchor=(1.2, 1.0))

So we see that more of the third class passengers embarking at S were male, but only by a small margin compared to C; that is probably not enough to explain the lower survival rate, so let's explore further:
g = sns.factorplot(x='Pclass', y='Survived', hue='Sex', col='Embarked', data=dataset, ci=95.0)
# ci = confidence interval (set to 95%)

What's interesting is that we see that third-class female passengers had a much lower survival probability if they embarked at S compared to both C and Q. This could partly explain why survival for Pclass 3 is lower for S than Q. But why would third class females be less likely to survive for Embarked = S ?
data_subset = dataset[dataset['Pclass']==3]
data_subset = data_subset[data_subset['Sex']=='female']
table = pd.crosstab(data_subset['Embarked'], data_subset['FamilySize'])
print('\n', table)
table_fractions = table.div(table.sum(1).astype(float), axis=0)
g = table_fractions.reindex(['S', 'C', 'Q']).plot(kind="bar", stacked=True, colormap='coolwarm')
plt.xlabel('Embarked')
plt.ylabel('Fraction of Total')
plt.title('FamilySize of Females in Pclass=3')
plt.tight_layout()
leg = plt.legend(title='FamilySize', loc=9, bbox_to_anchor=(1.2, 1.2))

It's possible that the lower third-class female survival rate for Embarked=S is related to the fact that a larger fraction of females in S have a large FamilySize (5 or higher), which we know has overall poorer survival rates.
What about passenger age? Let's look at how Age was distributed among Female passengers at each port of embarkment.
plt.figure(figsize=(10,5))
g = sns.violinplot(x="Embarked", y="Age", hue="Survived",
data=data_subset, split=True, palette='Set1', title='Female Passenger Age Distributions')

So another clue is that we see S had more female children, but surprisingly a larger proportion of these children died compared to C and Q. So let's look at survival of third-class female passengers under the age of 16 (e.g. children).
# survival of third-class female children
data_subset = data_subset[data_subset['Age'] < 16]
table = pd.crosstab(data_subset['Embarked'], data_subset['Survived'])
print('\n', table)
table_fractions = table.div(table.sum(1).astype(float), axis=0)
g = table_fractions.reindex(['S', 'C', 'Q']).plot(kind="bar", stacked=True,
colormap='coolwarm_r')
plt.xlabel('Embarked')
plt.ylabel('Fraction of Total')
plt.title('Survival of Female Children in Pclass=3')
plt.tight_layout()
leg = plt.legend(title='Survived', loc=9, bbox_to_anchor=(1.2, 1.0))

Q had only one female child and she survived. C had a small number, 11, of which 9 survived. In S, only one third survived. This is very surprising as this is well below the univariate female survival rate of 70%, and total pclass=3 female survival rate of 50%.
How does this compare against family size? We'll include male children in our plots, as a benchmark:
data_subset = dataset[dataset['Pclass']==3]
data_subset = data_subset[data_subset['Age'] < 16]
g = sns.factorplot(x="FamilySize", y="Survived", hue="Sex",
col="Embarked", data=dataset, ci=95.0)
print('Survival of Children Under 16, Pclass=3')

So the drop in survival for female children indeed seems to be tied to FamilySize. By now it appears that the FamilySize feature is responsible for the lower survival for PClass=3 in emabarked=S, as it is somehow tied to a larger fraction of the female passengers perishing.
g) A Closer Look at GroupType and GroupSize¶
Let's examine how Survival vs. GroupSize might vary with GroupType:
# focus only on groupsize < 5
plt.figure(figsize=(8,5))
g = sns.barplot(x="GroupSize", y="Survived", hue="GroupType", data=dataset[dataset['GroupSize'] < 5], palette='Set1')
plt.tight_layout()
leg = plt.legend(title='GroupType', loc=9, bbox_to_anchor=(1.15, 1.0))

We notice:
- For GroupSize=2, it is clearly advantageous to belong to a Family group rather than Non-Family.
It would also be interesting to explore the relationships GroupSize and GroupType have with other variables such as Sex, PClass, and Embarked. Some questions we ask:
- Are there differences in which GroupTypes and GroupSizes men and women tend to belong to?
- Do larger groups (the ones with poorer survival) tend to be in a higher or lower passenger class?
- What class do our lone travellers tend to belong to, and where do they typically embark?
# Sex distribution across GroupSize
table = pd.crosstab(dataset['GroupSize'], dataset['Sex'])
print('\n', table)
table_fractions = table.div(table.sum(1).astype(float), axis=0)
g = table_fractions.plot(kind="bar", stacked=True)
plt.xticks(rotation=0)
plt.xlabel('GroupSize', weight='bold')
plt.ylabel('Fraction of Total')
plt.tight_layout()
leg = plt.legend(title='Sex', loc=9, bbox_to_anchor=(1.15, 1.0))
# Sex distribution across GroupType
table = pd.crosstab(dataset['GroupType'], dataset['Sex'])
print('\n', table)
table_fractions = table.div(table.sum(1).astype(float), axis=0)
g = table_fractions.plot(kind="bar", stacked=True)
plt.xticks(rotation=0)
plt.xlabel('GroupType', weight='bold')
plt.ylabel('Fraction of Total')
plt.tight_layout()
leg = plt.legend(title='Sex', loc=9, bbox_to_anchor=(1.15, 1.0))


Findings:
- Our proportions of male vs. female passengers for each GroupSize mirrors what we have already found for FamilySize.
- As with FamilySize, we see that the male proportion of GroupSize tends to decrease between 1 and 4. This time we also see it clearly begin increasing again for GroupSizes 5 and higher. Since we know males in general have a much lower survival probability than females, this is seems to be at least partially responsible for the trends seen earlier for GroupSize. However, it is clearly not the whole story, as we see we still have a sizable female fraction for GroupSizes > 4 even though those groups experienced a sharp dropoff in surival probability. The lower survival at higher GroupSizes might be driven by those larger groups being predominantly of lower class, which we'll investigate soon.
- Unsurprisingly, the majority of lone passengers are male.
- Females have a slightly larger presence in Family groups compared to mixed and non-Family.
Let's look at female and male survival as a function of GroupType and GroupSize:
g = sns.factorplot(x="GroupSize", y="Survived", hue="GroupType", col="Sex",
data=dataset[dataset['GroupType'] != 'IsAlone'], ci=95.0)

Findings:
- Interestingly, survival is best for females in Mixed groups, closely followed by Non-Family and then Family groups. Survival plummets at a GroupSize of 5 (except for the mixed case, which plummets at 6).
- At low GroupSizes, males do significantly better in Family groups than they do Non-Family groups.
Now let's look at the distribution of passenger classes:
# Class distribution for a given GroupSize
table = pd.crosstab(dataset['GroupSize'], dataset['Pclass'])
print('\n', table)
table_fractions = table.div(table.sum(1).astype(float), axis=0)
g = table_fractions.plot(kind="bar", stacked=True)
plt.xticks(rotation=0)
plt.xlabel('GroupSize', weight='bold')
plt.ylabel('Fraction of Total')
plt.tight_layout()
leg = plt.legend(title='Pclass', loc=9, bbox_to_anchor=(1.15, 1.0))

We find:
- GroupSize=1 (GroupType = IsAlone) tends to predominantly be 3rd-class passengers (hence Pclass, in addition to the large fraction of males, may be responsible for the low survival probability we found for IsAlone).
- For GroupSize 2-4, a comparatively smaller fraction of passengers belong to 3rd class.
This raises the question: to what extent is Pclass responible for the variation in survival among different GroupSizes?
# Survival Probability for GroupSize < 5 Given Pclass
plt.figure(figsize=(8,5))
g = sns.barplot(x="GroupSize", y="Survived", hue="Pclass", data=dataset[dataset['GroupSize'] < 5], palette='Set1')
plt.tight_layout()
leg = plt.legend(title='Pclass', loc=9, bbox_to_anchor=(1.15, 1.0))

Findings:
- We see that for each Pclass we retain a roughly linear trend of increasing survival with increasing GroupSize up to 4; at the same time, within a given GroupSize, there is also consistently a linear trend between surival and Pclass.
So is GroupSize a useful feature in its own right, or are its trends derivative from other features? There's one more thing to check: earlier we found that a higher fraction of males at lower GroupSizes could also be influencing the GroupSize survival trends. So let's isolate for one sex, and see if these distinctions between GroupSizes remains:
data_subset_1 = dataset[dataset['Sex']=='male']
data_subset_2 = dataset[dataset['Sex']=='female']
# Survival Probability for GroupSize < 5 Given Pclass
plt.figure(figsize=(8,5))
g = sns.barplot(x="GroupSize", y="Survived", hue="Pclass",
data=data_subset_1[data_subset_1['GroupSize'] < 5], palette='Set1')
plt.tight_layout()
plt.title('Male Passengers Only:')
leg = plt.legend(title='Pclass', loc=9, bbox_to_anchor=(1.15, 1.0))
plt.figure(figsize=(8,5))
g = sns.barplot(x="GroupSize", y="Survived", hue="Pclass",
data=data_subset_2[data_subset_2['GroupSize'] < 5], palette='Set1')
plt.title('Female Passengers Only:')
plt.tight_layout()
leg = plt.legend(title='Pclass', loc=9, bbox_to_anchor=(1.15, 1.0))


Findings:
- When we isolate for Sex, and for Pclass, the general trend of increasing survival with increasing GroupSize for GroupSizes 1 through 4 disappears! There are some small increases between GroupSize 2-3 for male passengers of Pclasses 2 and 3, but this might not be significant given the large confidence intervals.
- This tells us that the trends in GroupSize (below GroupSize=5) are predominantly derivative of the Pclass and Sex features.
- We might consider replacing GroupSize and FamilySize with a new feature called "LargeGroup" that is True for GroupSize > 4 and otherwise False.
h) The Impact of Age on Survival, Given Pclass and GroupSize¶
From earlier, we know that being a Child (Age < 16) benefits survival. We also saw that passengers aged 30-40 had a slightly higher survival rate than those aged 16-29 or 41-59. Furthermore, we saw that passengers aged 60+ had an overall lower survival rate.
Our aim now is to determine whether these differences are explainable entirely in terms of other features such as Pclass, or whether Age can offer additional, complementary predictive power.
First, let's see how Age is distributed among Pclass:
table = pd.crosstab(dataset['Pclass'], dataset['AgeBin'])
print(table)
table_fractions = table.div(table.sum(1).astype(float), axis=0)
g = table_fractions.plot(kind="bar", stacked=True)
plt.xticks(rotation=0)
plt.xlabel('Pclass', weight='bold')
plt.ylabel('Fraction of Total')
leg = plt.legend(title='AgeBin', loc=9, bbox_to_anchor=(1.1, 1.0))
table = pd.crosstab(dataset['AgeBin'], dataset['Pclass'])
print('\n', table)
table_fractions = table.div(table.sum(1).astype(float), axis=0)
g = table_fractions.plot(kind="bar", stacked=True)
plt.xticks(rotation=0)
plt.xlabel('AgeBin', weight='bold')
plt.ylabel('Fraction of Total')
leg = plt.legend(title='Pclass', loc=9, bbox_to_anchor=(1.1, 1.0))


Findings:
- Higher-class passengers were generally older.
- Pclass 1 has the highest fraction of older (41-59) or elderly (60+) passengers.
- The fraction of passengers aged 30-40 was relatively uniform across all 3 Pclasses.
- Pclass 3 had the largest proportion of young adults (16-29) and children (0-15).
These findings are interesting because they tell us that Pclass was not the underlying reason for higher survival for the 30-40 age group, and that the elderly fared poorly in spite of being predominantly Pclass=1.
It is also interesting that earlier we found the 41-59 bin to have only slightly higher survival than the 16-29 age bin, despite the former having highest proportion in Pclass=1 and the latter having highest proportion in Pclass=3, as if higher age is counteracting some of the benefit of higher class.
Let's examine the survival of different age bins within each Pclass:
plt.figure(figsize=(12,5))
g = sns.barplot(x="Pclass", y="Survived", hue="AgeBin", data=dataset, palette='Set1')
plt.tight_layout()
leg = plt.legend(title='AgeBin', loc=9, bbox_to_anchor=(1.15, 1.0))

Findings:
- Across all three Pclasses, there appears little difference between the 16-29 and 30-40 age bins.
- Within Pclasses 1 and 3, survival of the 41-59 bin appears lower than for younger passengers.
These findings suggest that the higher overall (univariate) survival we found for the 30-40 age group may simply be an artefact of (a) how those passengers are distributed among Pclasses and (b) how survival is influenced by Pclass, rather than an age of 30-40 being an advantage in of itself. However, we do see a general negative effect of age for the 41-59 and 60+ age bins.
How is this impacted by Sex?
g = sns.factorplot(x="AgeBin", y="Survived", hue="Sex", col="Pclass", data=dataset, ci=95.0)

Findings:
- Within Pclass=1, higher age is significantly worse for male survival than female survival.
- For Pclasses 2 and 3, both sexes are impacted similarly.
We can also check these trends against GroupSize, albeit by now we know that trends relating to GroupSize are predominantly derivative of the Sex and Pclass features.
table = pd.crosstab(dataset['AgeBin'], dataset['GroupSize'])
print('\n', table)
table_fractions = table.div(table.sum(1).astype(float), axis=0)
g = table_fractions.plot(kind="bar", stacked=True, colormap='coolwarm')
plt.xticks(rotation=0)
plt.xlabel('AgeBin', weight='bold')
plt.ylabel('Fraction of Total')
leg = plt.legend(title='GroupSize', loc=9, bbox_to_anchor=(1.1, 1.0))
# let's look only at GroupSizes 4 and under
subset = dataset[dataset['GroupSize'] < 5]
plt.figure(figsize=(12,5))
g = sns.barplot(x="GroupSize", y="Survived", hue="AgeBin", data=subset, palette='Set1')
plt.tight_layout()
leg = plt.legend(title='AgeBin', loc=9, bbox_to_anchor=(1.15, 1.0))
# let's make our factorplot easier to read by only considering the middle three AgeBins
subset = subset[subset['AgeBin'] != '0-15']
subset = subset[subset['AgeBin'] != '60+']
g = sns.factorplot(x="GroupSize", y="Survived", hue="AgeBin", data=subset, col='Pclass', ci=95.0)



Findings:
- 'Unfavourable' GroupSizes are not the reason for the lower survival for AgeBins 41-59 and 60+, because we see those AgeBins in fact tend to have a greater proportion of passengers in 'favourable' GroupSizes (2-4), compared to the younger 16-29 and 30-40 bins.
- In general, AgeBin 41-59 had lower survival than younger bins irrespective of Pclass and GroupSize.
Conclusions:
- Higher passenger age, specifically 41+ years, has a negative impact on survival, which is most pronounced for first-class males, and is not derivative of the Pclass composition of these Age bins (in fact, it goes against the Pclass trend, since older passengers tend to be of a higher Pclass).
i) Do Groups Tend to Survive or Perish Together?¶
Next, we set out to answer a simple question: do groups tend to survive or perish together? That is to say, if you know that at least one member of a given group has perished, can this influence the likelihood of other members of that group surviving?
To investigate such relations, we will focus our attention only on groups of size 2-4 that lie entirely within our training set (i.e. for which we have complete knowledge about survival upon which to base our statistics).
How could this potentially be useful? If we imagine treating the class probabilities predicted by our trained machine-learning model as prior probabilities in the Bayesian sense, then when making our predictions on the test set, we could consider using any available knowledge of same-GroupID member survival from the training set to obtain posterior probabilities that further refine our predictions about a test-set passenger's survival. Or, alternatively, we could simply include 'GroupNumSurvived' or a derived feature as part of our training set.
Let's first obtain the distribution of our passengers across GroupNumSurvived for different Group Sizes:
data_subset = dataset[dataset['GroupSize'] == dataset['GroupNumSurvived'] + dataset['GroupNumPerished']]
data_subset = data_subset[data_subset['GroupSize'] > 1][data_subset['GroupSize'] < 5]
table = pd.crosstab(data_subset['GroupSize'], data_subset['GroupNumSurvived'])
print(table)
table_fractions = table.div(table.sum(1).astype(float), axis=0)
g = table_fractions.plot(kind="bar", stacked=True)
plt.xticks(rotation=0)
plt.xlabel('GroupSize', weight='bold')
plt.ylabel('Fraction of Total')
plt.tight_layout()
leg = plt.legend(title='NumGroup \nSurvived', loc=9, bbox_to_anchor=(1.15, 1.0))

We see from the printed table that there are few samples for GroupSize=4 upon which to base our statistics, so we focus here only on GroupSizes 2 and 3.
If we know the survival outcome of one passenger from a given GroupID from our training set, can that provide us with any information about the survival probability for a passenger in the test set that belongs to the same GroupID? Unfortnately, for GroupSize=2, since the probability is distributed roughly evenly between 0, 1, and 2 passengers surviving, knowledge that at least one passenger has survived is not particularly helpful in determining whether the second passenger survived.
On the other hand, for GroupSize=3, the uneven distributions tell us that there is indeed some information to be gained. In this case, looking at the barplot, if at least one passenger from a given GroupID is known to have survived, then we eliminate the bottom blue segment, renormalize the green+red+purple segments to sum to unity, and compare the fraction of red+purple to the fraction of green. We compute prior and posterior probabilities explicitly below:
print('*** GROUPSIZE=2 ***')
print('\nPrior Probability of a Passenger\'s Survival:')
print('%.4f' % data_subset[data_subset['GroupSize'] == 2]['Survived'].mean())
print('\nPosterior Probability given that at least one passenger from that GroupID survived:')
print('%.4f' % (table.values[0][2]/(table.values[0][1:3].sum())))
print('\n*** GROUPSIZE=3 ***')
print('\nPrior Probability of a Passenger\'s Survival:')
print('%.4f' % data_subset[data_subset['GroupSize'] == 3]['Survived'].mean())
print('\nPosterior Probability given that at least one passenger from that GroupID survived:')
print('%.4f' % ((table.values[1][2] + table.values[1][3])/(table.values[1][1:5].sum())))
print('\nPosterior Probability given that at least two passengers from that GroupID survived:')
print('%.4f' % ((table.values[1][3])/(table.values[1][2:5].sum())))
The above affirms that for GroupSize=2, even if we know one passenger from a group has survived, this does little to change the likelihood that the other has.
For GroupSize=3, it appears that if we know one passenger has survived, the likelihood of second surviving is very high, about 26% higher than if we know nothing. However, if we already know that two members of that group have survived, the likelihood that the third survived drops dramatically.
For completeness, we check whether these general trends hold true when we consider only familes, as opposed to mixed groups:
data_subset = dataset[dataset['GroupSize'] == dataset['GroupNumSurvived'] + dataset['GroupNumPerished']]
data_subset = data_subset[data_subset['GroupSize'] > 1][data_subset['GroupSize'] < 5]
data_subset = data_subset[data_subset['GroupType'] == 'Family']
table = pd.crosstab(data_subset['GroupSize'], data_subset['GroupNumSurvived'])
print('*** FAMILY-ONLY GROUPS ***')
print(table)
table_fractions = table.div(table.sum(1).astype(float), axis=0)
g = table_fractions.plot(kind="bar", stacked=True)
plt.xticks(rotation=0)
plt.xlabel('GroupSize', weight='bold')
plt.ylabel('Fraction of Total')
plt.tight_layout()
leg = plt.legend(title='NumGroup \nSurvived', loc=9, bbox_to_anchor=(1.15, 1.0))

We observe that overall, there is a smaller fraction of Family-only groups that perish in their entirety. For GroupSize=2, there is again little difference in the fraction of groups where both members survive versus where only one survives.
1.5 - Summary of Key Findings¶
The most important features appear to be Sex, Pclass, Age, and GroupSize (for GroupSize > 4), in that order. Some of our other interesting findings, that can help guide us in feature selection and classifier creation, are as follows:
- Females: Female Pclass 1 passengers nearly all survived (95%+). Most Pclass 2 female passengers also survived (90%+). This drops sharply for Pclass 3 female passengers (to about 50%), but being a female child increases survival by roughly 5%.
- Males: Most male children in Pclass 1 and 2 survive. For Pclass 3, male children are only about 20% more likely to survive than male adults. For male adults, survival is around 40% for Pclass 1, and around 15% for Pclass 2 and 3.
- Age: Survival increases for children under 16. Going by our AgeBin feature, survival decreases for passengers of age 41+, which is most pronounced for first-class males, and is not derivative of other features.
- FamilySize and GroupSize: When we isolate for Sex and Pclass, we find that the trend of increasing survival with increasing FamilySize or GroupSize (up to a value of 4) disappears! This tells us these trends were derivative of the Pclass and Sex features. However, the sharp drop in survival for FamilySize and GroupSize of 5 or larger is not entirely explainable from just Sex and Pclass. This motivates the creation of a new feature, "LargeGroup", denoting GroupSize > 5.
- GroupType: Passengers in GroupType "Alone" fare the worst, but these also tend to be predominantly male passengers of Pclass 3, who fare poorly anyway. For GroupSize=2, we found that passengers belonging to a Family GroupType had a greater chance of survival than thoses belonging to a non-family GroupType, but as already stated, the behaviour of GroupSize below 5 appears to be mostly determined by Sex and Pclass, so this is not very interesting. If we consider only Sex and not Pclass, survival for females appears best in the 'Mixed' GroupType, closely followed by Non-Family and then Family groups. At low GroupSizes, males do significantly better in Family groups than non-family groups.
- SplitFare: We found that any predictive power of SplitFare within each Pclass appeared to be explainable by the associated GroupSizes (with GroupSizes 2, 3, and 4 having better survival) which in turn is explainable via the composition of these GroupSizes in terms of Pclass and Sex. So it would appear that SplitFare doesn't offer any advantage over Pclass.
- Embarked: We found that third-class female passengers appeared to have a much lower survival probability if they embarked at S compared to both C and Q. But it appears this is simply due to the fact that a greater proportion of these females belonged to large GroupSizes (5 and up) which we know has a negative impact on survival. Embarked itself does not appear to offer any additional predictive power, and is therefore not a very interesting feature.
2) Data Pre-Processing¶
2.1 - Checking Data Consistency¶
When training predictive models, our underlying assumption is that the data we feed our model is correct and accurate. However, this is indeed an assumption, and is not necessarily always true. Here we check our data for inconsistencies and flag entries that are suspicious.
Earlier, when defining Groups for passengers sharing the same ticket, we checked for cases where FamilySize=1 but the GroupType was labelled 'Family' due to shared surnames. We found 7 such instances, and determined that these could be passengers with second-degree relations (such as cousins), which are not counted in the ParCh or SibSp metrics.
We also checked for cases where FamilySize > 1 but GroupType = 'NonFamily'. In most cases, we found many of such cases to be an artefact of females who were travelling under a maiden name rather than their spouse's surname, and we corrected their GroupType to 'Family' accordingly.
Some additional things we can check for are:
- Agreement between Sex and Title (obviously Miss or Mrs should be female, Mr should be male)
- Agreement of Fare and Embarked port among passengers sharing a ticket
- Age/Parch consistency (see below)
a) Title/Sex Inconsistencies¶
# Checking for Title/Sex inconsistencies
flagged_ids = []
for index, row in dataset.iterrows():
if row['Title'] in ['Mr', 'Mister', 'Master']:
if row['Sex'] != 'male':
flagged_ids.append(index)
elif row['Title'] in ['Miss', 'Mrs', 'Mme', 'Mlle']:
if row['Sex'] != 'female':
flagged_ids.append(index)
print('Number of Sex/Title Inconsistencies:', len(flagged_ids))
b) Embarked/Fare Inconsistencies within Groups¶
# Checking for group inconsistencies in Embarked or Fare
flagged_group_ids = []
for (group_id, group) in dataset.groupby('GroupID'):
if len(set(group['Embarked'].values)) != 1 or len(set(group['Fare'].values)) != 1:
flagged_group_ids.append(group_id)
print('Number of Embarked/Fare Inconsistencies within shared ticket groups:',
len(flagged_group_ids))
# Exploring the flagged Embarked/Fare group inconsistencies
feature_list = ['GroupID', 'GroupSize', 'Name', 'PassengerId', 'Ticket', 'Fare', 'Embarked']
dataset[dataset['GroupID'].isin(flagged_group_ids)][feature_list].sort_values('GroupID').head(10)
Findings:
For GroupID=692, we find the only case where passengers sharing a ticket are listed has having slightly different fares. It's not clear why this is the case, but the fare values are sufficiently close enough that we need not take action.
For GroupIDs 63 and 837, not all passengers are listed as having embarked at the same port. We can do some quick research about these passengers to check whether this is an error.
An online search of biographic profiles for these passengers shows that Mr. Alexander Cairns and Miss Augusta Serepeca both embarked in Southhampton; so the 'C' listed as embarked for the latter is an error. Likewise, our research finds that Miss Amelia Bissette embarked in Cherbourg, not Southhampton. We make these corrections below.
# Corrections
dataset['Embarked'][dataset['PassengerId'] == 843] = 'S'
dataset['Embarked'][dataset['PassengerId'] == 270] = 'C'
## Verification
# dataset[dataset['GroupID'].isin(flagged_group_ids)][feature_list].sort_values('GroupID').head(10)
c) Age/Parch Inconsistencies¶
Finally, if you are a passenger below the age of 16, it's safe to assume that you are a child, and hence that your value for 'Parch' should be no greater than 2. We check this below:
# Checking for group inconsistencies in Age/Parch
flagged_ids = []
for _, row in dataset.iterrows():
if row['Age'] <= 16:
if row['Parch'] > 2:
flagged_ids.append(row['PassengerId'])
print('Number of Sex/Title Inconsistencies:', len(flagged_ids))
We found a single inconsistency. Let's investigate this in more detail:
dataset[dataset['PassengerId'].isin(flagged_ids)].head()
This appears to be a mistake. A little background research shows that Mr. William Neal Ford boarded with his mother and three siblings:
- Margaret Ann Watson Ford (mother)
- Robina Maggie Ford (sister)
- Dollina Margaret Ford (sister)
- Edward Watson Ford (brother)
It appears that his entries for Parch and SibSp may have been accidentally swapped. Let's double check with other members of his GroupID:
flagged_group_id = dataset[dataset['PassengerId'].isin(flagged_ids)]['GroupID'].values
print('GroupID:', flagged_group_id)
dataset[dataset['GroupID'].isin(flagged_group_id)].head()
Margaret Ann Watson Ford (mother) did have one sibling on board, namely Eliza Johnston. However, however her Parch count is clearly incorrect (it should be 4). The siblings Edward, 'Doolina' [sic], and Robina all have Parch=2 (should be 1) and SibSp=2 (should be 3). Further research shows that Margaret Ann Watson Ford's husband had deserted her and her family, so we can verify that he wasn't on board. So it seems in all of these cases that somehow William Neal Ford was treated as the husband of his own mother (whoops!) when the entries for Parch and Sibsp were filled! Let's correct this:
# Corrections
sibling_passengerIds = [87, 148, 437, 1059]
mother_passengerId = 737
dataset['Parch'][dataset['PassengerId'].isin(sibling_passengerIds)] = 1
dataset['Parch'][dataset['PassengerId'] == mother_passengerId] = 4
dataset['SibSp'][dataset['PassengerId'].isin(sibling_passengerIds)] = 3
## Verification
# dataset[dataset['GroupID'].isin(flagged_group_id)].head()
2.2 - Identifying Outliers¶
Outliers are defined as samples that are exceptionally far from typical values. They may be the result of errors in data recording, or they may in fact contain important information significant to the task at hand. Identifying and understanding outliers is an therefore an important task in ensuring that the data we use to train our models is of high quality.
There are several mathematical models for identifying outliers, but the choice of criteria is ultimately subjective. Some common models include:
- z-score (parametric) or the IQR method (non-parametric)
- linear regression models, e.g. with Principal Component Analysis (PCA) or Least-Mean Squares (LMS)
- proximity-based models such as cluster analysis including Dbscan
The two most basic models, applicable to univariate analysis, are the z-score (e.g. how many standard deviations away from the mean is a given sample) and the interquartile range (IQR) method. The z-score is a parametric method that assumes the data fits a Gaussian model and is symetrically distributed, while the IQR method is non-parametric and makes no such assumptions.
We will look only at univariate outliers using the more-general IQR method. The IQR is defined as the difference between the value denoting the 3rd quartile (Q3, delineating the bottom 75% of all values) and the value denoting the 1st quartile (Q1, delineating the bottom 25% of all values). Exactly 50% of all datapoints are contained within the IQR. Outliers are typically taken to be datapoints that fall beyond the "Tukey Fences" (named after mathematician John Tukey of Box-Plot and Fast-Fourier-Transform fame) defined by $(Q1 - 1.5*IQR)$ and $(Q3 + 1.5 *IQR)$, i.e. more than 1.5 times the interquartile range below the first quartile or above the third quartile. The motivation behind the factor of 1.5 x IQR is that it corresponds approximately to 3 standard deviations away from the mean (the 99.7% confidence interval) in the special case that our data is symmetrically Gaussian distributed; more generally, it is a rough analogy of this common "three-sigma" rule of thumb.
a) Finding the Outliers¶
Below we define a function that returns the PassengerID of all data entries containing outliers within the specified feature list, as well as a count of how many different features for that PassengerID contained outliers:
def get_outliers_IQRmethod(dataframe, features, fence_factor=1.5):
"""
Returns a list of PassengerIds for which outliers were detected, as well as the number of outlying features
for that passenger, based on the interquartile range (IQR) method.
:param dataframe: Our data, as a Pandas dataframe object.
:param features: A list of features we want to search for outliers.
:param fence_factor: How many IQRs below Q1 or above Q3 a point must be, for it to be considered
an outlier; nominally 1.5 for Tukey fences.
:return ids: A sorted list of PassengerIds where outliers were detected
:return counts: The corresponding list of how many feature outliers were counted per entry in 'ids'.
"""
tagged_ids_ = []
for feature_ in features:
data_ = dataframe.dropna(subset=[feature_]).copy() # drop missing entries
q1, q3 = np.percentile(data_[feature_], [25, 75]) # obtain 1st and 3rd quartiles
iqr = q3 - q1 # interquartile range (positive-valued by definition)
print('Feature:', feature_)
print('--> Q1 is:', q1)
print('--> Q3 is:', q3)
print('--> IQR is:', iqr)
outlier_ids_ = data_[(data_[feature_] < q1 - fence_factor*iqr)
| (data_[feature_] > q3 + fence_factor*iqr)]['PassengerId'].values
tagged_ids_.extend(outlier_ids_)
# note: using extend instead of append to avoid nested lists
# tally up outlier occurences with Counter
outlier_counter = Counter(tuple(tagged_ids_)) # tuple() makes input hashable
ids_ = outlier_counter.keys() # gives the unique set of tagged indices
counts_ = outlier_counter.values()
print('Number of Flagged Entries:', len(ids_))
ids_, counts_ = zip(*sorted(zip(ids_, counts_))) # sort in ascending order
return ids_, counts_
def outlier_filter(ids_, counts_, count_threshold=2):
"""
Returns only the PassengerIds in which the number of outlying features counted was 'count_threshold'
or greater.
"""
return [i for i, count_ in zip(ids_, counts_) if count_ >= count_threshold]
Some features we may consider examining are Fare, Age, and FamilySize. It's useful here to look again at some basic univariate statistics:
feature_list = ['Fare', 'Age', 'FamilySize']
dataset[feature_list].describe()
The 25% and 75% rows show us the values associated with the 1st and 3rd quartiles respectively. We find immediately:
- Fare: The max value of Fare is 512. We might consider examing Fare outliers within each Pclass, rather than across all Pclasses, to ensure that high fare values are being considered within the appropriate context.
- Age: There aren't any obviously erroneous (i.e. non-physical) entries for Age. We won't worry about outliers in Age as we can easily understand the IQR-method outliers (which we can easily calculate to be seniors above 66 in this case).
- FamilySize: The max value of FamilySize is 11. This is many IQRs from Q3 due to the large number of lone passengers. We might consider only looking at FamilySize outliers for cases where GroupType is not 'Alone'.
Let's first look at FamilySize for GroupTypes != IsAlone:
FS_outlier_ids, _ = get_outliers_IQRmethod(dataset[dataset['GroupType'] != 'IsAlone'], ['FamilySize'])
# let's look at some of the flagged entries
feature_list = ['PassengerId', 'Name', 'FamilySize', 'GroupType', 'Parch', 'SibSp']
dataset[dataset['PassengerId'].isin(FS_outlier_ids)][feature_list].head(10)
This seems to be flagging passengers belonging to groups with FamilySize 5 or greater. Let's now look at the more nuanced case of Fare. There are several versions of this variable we can consider (Fare, SplitFare, and their log10 versions). Using Seaborne's boxplots, we can directly visualize the IQR-method outliers as points on these plots:
Note: the boxes themselves give the limits of Q1 and Q3, subdivided by a black line at Q2, while the whiskers show the max and min values of the data range excluding the outliers.
sns.set(font_scale=1.5)
plt.style.use('seaborn-whitegrid')
fig = plt.figure(figsize=(14, 5))
fig.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=0.3, hspace=0.5)
ax = fig.add_subplot(1, 2, 1)
ax = sns.boxplot(x="Pclass", y="Fare", data=dataset)
ax.set_yscale('log')
ax = fig.add_subplot(1, 2, 2)
ax = sns.boxplot(x="Pclass", y="SplitFare", data=dataset)
ax.set_yscale('log')
sns.set(font_scale=1.5)
plt.style.use('seaborn-whitegrid')
fig = plt.figure(figsize=(14, 5))
ax = fig.add_subplot(1, 2, 1)
ax = sns.boxplot(x="Pclass", y="log10Fare", data=dataset)
ax = fig.add_subplot(1, 2, 2)
ax = sns.boxplot(x="Pclass", y="log10SplitFare", data=dataset)


Earlier we had said that SplitFare seems to be better than Fare at clearly delineating between classes. And indeed there was evidence to suggest that the Ticket price was cumulative for all passengers. So let's work with SplitFare. But should we use a linear or logarithmic representation? Let's use linear in this case (the choice is subjective). We'll look for outliers in each individual class separately, and then pool the flagged passengers together at the end. Using the typical 1.5 x IQR Tukey fences returns a heck of a lot of outliers (160), so we'll widen our fences to 3.0 x IQR to focus on those points that are furthest from typical values.
splitfare_outlier_ids = []
for pclass_ in [1, 2, 3]:
print('\nPclass:', pclass_)
outlier_ids, _ = get_outliers_IQRmethod(dataset[dataset['Pclass'] == pclass_], ['SplitFare'], fence_factor=3.0)
splitfare_outlier_ids.extend(outlier_ids)
print('Note: mean SplitFare is:', dataset[dataset['Pclass']==pclass_]['SplitFare'].mean())
print('\nTotal Number of Flagged Entries:', len(splitfare_outlier_ids))
Examining the flagged entries:
feature_list = ['PassengerId', 'Name', 'GroupSize', 'GroupID', 'Pclass', 'Fare', 'SplitFare', 'Ticket']
dataset[dataset['PassengerId'].isin(splitfare_outlier_ids)][feature_list].sort_values(['Pclass', 'GroupID']).head(31)
Comments:
- Passengers in Pclass = 1: Flagged passengers had some truly high values for Fare and SplitFare! We can try to verify these numbers with research.
- Passengers in Pclass = 2: Flagged passengers had 0.0 listed for Fare price. We should investigate the reason why.
- Passengers in Pclass = 3: We have two instances of truly high Pclass=3 splitfares (for Mr. Ingvald Hagland Mr. Konrad Hagland) that exceed the mean SplitFare for Pclass=2! We have one case (for GroupID=788) where 0.0 was given as the Fare price. We also have several other cases of unusually low SplitFare such as for GroupIDs 542, 478, and 234.
Let's see if we can better understand or explain some of these SplitFare outliers. Findings from online research:
Pclass = 1: The high ticket prices for the Cardezas and their co-travellers (at £512 cumulative) is correct! They occupied one of the two most luxurious suites on board. You can read about their accomodations here. The high ticket price for Mr. Quigg Baxter is also verifiable.
Pclass = 2: All of the second-class passengers with a £0.00 listed fare belonged to the nine-person "guarantee group" of Harland and Wolff employees (the Titanic's shipbuilders) that were honorarily chosen to accompany the Titanic on its maiden voyage to oversee its smooth running and identify any necessary improvements. All members of this group travelled free of charge. Six were in second-class, which we see in our table above. The three other members, including the Titanic's chief naval architect Mr. Tomas Andrews, travelled first class. The first-class members of the guarantee group also have fares of £0.00, but our wide IQR fences did not treat these as outliers. We will nonetheless make note of this. The full list of the nine-member guarantee-group, along with their passenger ids in parentheses, is given below. For the curious, more information about them can be found on this National Geographic webpage.
The Guarantee Group:
- ANDREWS, Mr Thomas (807)
- CAMPBELL, Mr William (467)
- CHISHOLM, Mr Roderick (1158)
- CUNNINGHAM, Mr Alfred Fleming (414)
- FROST, Mr Anthony Wood (482)
- KNIGHT, Mr Robert (733)
- PARKES, Mr Francis (278)
- PARR, Mr William Henry Marsh (634)
- WATSON, Mr Ennis Hastings (675)
- Pclass = 3: Our research verifies the unusually low splitfares for GroupIDs 234, 243, 478, 542, and 742. In the first four cases, the combination of large families and likely a family-rate discount helped bring SplitFare down. For Artur Olsen, he had been transferred as a passenger from another ocean linear (the Philadelphia) whose voyage was cancelled, so it's possible his low ticket price reflects a discount or the lower fare he paid for the Philadelphia. On the other hand, the high-fare entries for Mr. Ingvald Hagland and Mr. Konrad Hagland appear incorrect. External sources show their ticket price as being £6 19s 4d (six pounds, 19 shillings and fourpence = £6.966); it may be that the 19 shillings were erroneously recorded as 19 pounds --- we will correct this. As for the passengers with a fare of £0.00, it turns out these were employees of the company American Line, who were due to sail with the Philadelphia, but were transferred to the Titanic when the Philadelphia's voyage was cancelled. Hence why their ticket is labelled "LINE". It's not clear whether these were treated as 'passengers', or whether they served as crew but in passenger cabins.
We will decide what to do about these outliers shortly. But first, let's fix the incorrect fares for the Haglands:
# correcting the Fare entry for the Mr. Konrad and Ingvald Hagland
passenger_ids = [452, 491]
dataset['Fare'][dataset['PassengerId'].isin(passenger_ids)] = 6.966
dataset['SplitFare'][dataset['PassengerId'].isin(passenger_ids)] = 6.966 # GroupSize=1 for both
# let's also remove these passengers from our flagged splitfare outlier IDs
print('Length of splitfare_outlier_ids Before:', len(splitfare_outlier_ids))
splitfare_outlier_ids = [x for x in splitfare_outlier_ids if x not in passenger_ids]
print('Length of splitfare_outlier_ids After:', len(splitfare_outlier_ids))
# viewing our changes
feature_list = ['PassengerId', 'Name', 'Fare', 'SplitFare']
dataset[feature_list][dataset['PassengerId'].isin(passenger_ids)].head()
As a side note, we can also identify passengers who had outliers for multiple features:
combined_flagged_ids = tuple(FS_outlier_ids) + tuple(splitfare_outlier_ids)
combined_outliers = Counter(tuple(combined_flagged_ids)) # tuple() makes input hashable
unique_ids = combined_outliers.keys() # gives the unique set of tagged Passenger IDs
outlier_counts = combined_outliers.values() # gives corresponding number of outlying features for that ID
unique_ids, outlier_counts = zip(*sorted(zip(unique_ids, outlier_counts))) # sort in ascending order
filtered_outlier_ids = outlier_filter(unique_ids, outlier_counts, count_threshold=2)
print('Number of passengers having more than one outlying feature:', len(filtered_outlier_ids))
print('Flagged PassengerIds:', filtered_outlier_ids)
b) What To Do With Our Outliers?¶
On one hand, some (but not all) machine learning algorithms can be highly sensitive to outliers, adversely impacting model accuracy. On the other hand, we want to be careful when considering the removal of outliers as they may contain information significant to our model. A safe rule-of-thumb is to remove an outlier only when there is clear evidence that it represents an error in data recording or input. If we can verify that an outlier in fact represents a true observation, we should generally include it in our model training.
There can be extenuating circumstances, however, such as if there exists evidence to suggest that the outlier, given its context, belongs to a model that should be treated separately from the model we are considering. For example, we have noticed from our Fare outliers that several of our 'passengers' were actually employees of the shipbuilding company or of a related ocean liner (e.g. the 'guarantee group' and the American Line employees). There is historical evidence to suggest that crew survival should be treated as a separate model. One can find numerous reports of the technical staff taking heroic efforts or giving passengers full lifeboat priority and choosing to go down with the ship due to their principles and feeling of responsibility. The Titanic's orchestra continued to play on the top deck to help calm passengers nerves', and perished. The Titanic's chief naval architect Thomas Andrews (who perished according to our traning dataset) was seen tirelessly searching staterooms to urge reluctant passengers to go up on deck. And from our ealier KDE univariate plot of Fare, we found that all those with a Fare entry of 0.0 died! So we may choose to withold these particular samples from our model training.
If we are still concerned about the impact of a non-erroneous outlier on our model, there are several means of assessing its influence. Some of these methods, not covered here, include regression-based techniques such as:
- Influence on Single Fitted Value (DFITS)
- Influence on All Fitted Values ("Cook's Distance")
We will take the following actions listed below:
- We have 8 'passengers' who are actually employees of the Titanic's shipbuilders (the 'guarantee group') and whose survival we believe fits a 'crew' model rather than the 'passenger' model. We will label these individuals with a new feature, 'IsGG', and experiment with including them versus excluding them from our model training.
- We have four passengers belonging to another Ocean Liner company (American Line); we don't know whether these employees were on 'active duty' (e.g. to effectively cover their voyage on the Titanic). We will choose to keep them as part of our training dataset.
- All other 'outliers' were either corrected or verified. We will keep these in our training dataset.
Creation of the 'IsGG' feature for the Guarantee Group:
guarantee_group_ids = [278, 414, 467, 482, 634, 675, 733, 807, 1158]
dataset['IsGG'] = np.where(dataset['PassengerId'].isin(guarantee_group_ids), 1, 0)
feature_list = ['PassengerId', 'Name', 'Pclass', 'Fare', 'Age', 'IsGG']
dataset[feature_list][dataset['PassengerId'].isin(guarantee_group_ids)].head(20)
2.3 - Dealing with Missing Feature Entries¶
We will consider missing entries for the following features:
- Age (263)
- Embarked (2)
- Fare (1)
Note that in fact we can look up these missing values via online research. However, here we shall take the approach typical of most datasets, and work only with the information that we have (as if other sources for filling this data weren't available).
a) Embarked and Fare¶
Embarked and Fare can be dealt with through simple imputation, given the low number of missing values. Let's view these entries:
# showing the entries missing Fare
feature_list = ['PassengerId', 'Name', 'Fare', 'SplitFare', 'Sex', 'Pclass', 'GroupSize']
print('Passengers missing \'Fare\' Entry:')
dataset[feature_list][dataset['Fare'].isnull()].head()
# showing the entries missing Embarked
feature_list = ['PassengerId', 'Name', 'Embarked', 'Sex', 'Pclass', 'GroupSize', 'GroupID']
print('Passengers missing \'Embarked\' Entry:')
dataset[feature_list][dataset['Embarked'].isnull()].head()
For Embarked, we choose to substitute the most common embarkment point for a member of the same Pclass and Sex.
For Fare, for which the one missing entry corresponds to a lone passenger in Pclass=3, we will substitute the mean Fare for members of Pclass=3 having GroupSize=1.
These actions are taken below:
# fare correction
mean_val = dataset[((dataset['Pclass'] == 3) &
(dataset['GroupSize'] == 1))][['Fare']].mean().values[0]
print('Mean \'Fare\' for lone traveller in Pclass = 3:', mean_val)
dataset['Fare'][dataset['PassengerId'] == 1044] = mean_val
dataset['SplitFare'][dataset['PassengerId'] == 1044] = mean_val
# embarked correction
mean_val = dataset[(dataset['Pclass'] == 1) & (dataset['Sex'] == 'female')]['Embarked'].value_counts().index[0]
print('Most common \'Embarked\' for females in Pclass = 1:', mean_val)
dataset['Embarked'][dataset['PassengerId'].isin([62, 830])] = mean_val
# verifying our changes:
passengerid_list = [1044, 62, 830]
feature_list = ['PassengerId', 'Name', 'Fare', 'SplitFare', 'Embarked',
'Sex', 'Pclass', 'GroupSize']
dataset[feature_list][dataset['PassengerId'].isin(passengerid_list)].head()
Let's also re-apply the logarithmic Fare mapping to the entire dataset, to ensure that all of the features derived from Fare are up to date:
# repeat mapping to log10 scale
dataset['log10Fare'] = np.log10(dataset['Fare'].values + 1)
dataset['log10SplitFare'] = np.log10(dataset['SplitFare'].values + 1)
b) Age¶
Next up is Age, for which nearly 20% of all entries are missing. Our Exploratory Data Analysis showed that 'Age' was of significance to survival, especially for passengers 15 years or younger (i.e. children). And indeed there was a policy of 'Women and Children First' when filling the lifeboats. So it would be great if we can include this feature in our analysis. That leaves us with two choices: drop observations with missing entries (but that would be dropping too much of our training data!) or find a sensible way to estimate the values of the missing age entries.
As a first step, we can leverage our knowledge that all male passengers with the title 'Master' are aged 15 or under. We will assign such passengers an age that is the mean age of all other passengers with 'Master' as their title:
mean_val = dataset[dataset['Title'] == 'Master']['Age'].mean()
print('Mean Age of passengers with title \'Master\' : ', mean_val)
feature_list = ['PassengerId', 'Name', 'Age']
dataset[feature_list][(dataset['Title'] == 'Master') & (dataset['Age'].isnull())].head()
# application of new age values and verification
dataset['Age'][(dataset['Title'] == 'Master') & (dataset['Age'].isnull())] = mean_val
passengerid_list = [66, 160, 177, 710, 1136]
dataset[feature_list][dataset['PassengerId'].isin(passengerid_list)].head()
To estimate Age for the remaining missing entries, we can take advantage of how Age correlates with other features. Our earlier feature correlation plot in Section 1.4(a) only considered entries from our training dataset. Here we'll check the correlations across our entire dataset:
feature_list = ['Pclass', 'Age', 'SibSp', 'Parch', 'FamilySize', 'GroupSize']
plt.figure(figsize=(12,8))
sns.set(font_scale=1.5)
g = sns.heatmap(dataset[feature_list].corr(), square=True, annot=True, cmap='coolwarm', fmt='.2f')

As we can see, the features most strongly correlated with Age are: Pclass (-0.41), SibSp (-0.26), FamilySize (-0.25), GroupSize (-0.20), and Parch (-0.15). Let's take a quick look at Age trends within these features. We will also look at Age's dependence on Sex:
sns.set(font_scale=1.5)
plt.style.use('seaborn-whitegrid')
fig = plt.figure(figsize=(14, 5))
fig.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=0.3, hspace=0.5)
ax = fig.add_subplot(1, 2, 1)
ax = sns.boxplot(x='Sex', y='Age', data=dataset)
ax = fig.add_subplot(1, 2, 2)
ax = sns.boxplot(x='Pclass', y='Age', data=dataset)
fig = plt.figure(figsize=(14, 5))
fig.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=0.3, hspace=0.5)
ax = fig.add_subplot(1, 4, 1)
ax = sns.boxplot(x='GroupSize', y='Age', data=dataset)
ax = fig.add_subplot(1, 4, 2)
ax = sns.boxplot(x='FamilySize', y='Age', data=dataset)
ax = fig.add_subplot(1, 4, 3)
ax = sns.boxplot(x='Parch', y='Age', data=dataset)
ax = fig.add_subplot(1, 4, 4)
ax = sns.boxplot(x='SibSp', y='Age', data=dataset)


Comments:
- The difference in Age distributions between sexes appears negligible.
- We have already noted the clear trend of upper-class passengers being older.
- There is a discontinuity in the trend for Age vs. Parch. The reason is simple: a child can have at most 2 legal parents; if Parch > 2 then the passenger must be an adult.
We choose to fill missing age entries using the mean age of entries having matching Pclass, Parch, and SibSp values. We will not use the derived features GroupSize and FamilySize, as Parch and SibSp should be sufficient and adding further features whose values must be matched will reduce the sample sizes from which the means are computed.
index_missingAge = list(dataset['Age'][dataset['Age'].isnull()].index)
for i in index_missingAge:
age_estimate = dataset['Age'][((dataset['Pclass'] == dataset.iloc[i]['Pclass'])
& (dataset['Parch'] == dataset.iloc[i]['Parch'])
& (dataset['SibSp'] == dataset.iloc[i]['SibSp']))].mean()
dataset.loc[i, 'Age'] = math.ceil(age_estimate)
# verify that there are no NaN entries left:
print('Number of remaining missing Age entries:', dataset['Age'].isnull().sum())
We must remember to re-apply the creation of age-dependent engineered features, namely 'IsChild' and 'AgeBin':
# re-creation of IsChild
dataset['IsChild'] = np.where(dataset['Age'] < 16, 1, 0)
# re-creation of Age bins; see Section 1.3-b
bin_thresholds = [0, 15, 30, 40, 59, 90]
bin_labels = ['0-15', '16-29', '30-40', '41-59', '60+']
dataset['AgeBin'] = pd.cut(dataset['Age'], bins=bin_thresholds, labels=bin_labels)
Finally, let's re-check some of the feature trends we noted earlier in our Exploratory Data Analysis to see if they still hold after our imputation of so many Age values:
sns.set(font_scale=1.5)
plt.style.use('seaborn-whitegrid')
g = sns.barplot('AgeBin','Survived', data=dataset)

barplots(dataset, features=['IsChild'], cols=1, width=5, height=100, hspace=0.3, wspace=0.2)

univariate_kdeplots(dataset, ['Age'], cols=1, width=15, height=100, hspace=0.4, wspace=0.25)

Comments (compared to E.D.A. findings):
- AgeBin: Mean(Survived) has slightly decreased for AgeBin 0-15 from ~ 58% to around 52%, but we retain the same overall trend.
- IsChild: Mean(Survived) for IsChild=True has likewise decreased from ~ 58% to around 52%; survival for IsChild=False remains unchanged.
- Age KDE Plot: In the Kernel Density Estimate plot, the peak age for 'Perished' has shifted slightly to the right, from around Age=24 to around Age=27, and is slightly more prominent.
From what we can tell above, our imputation of Age has not significantly altered the trends we saw earlier in our Exploratory Data Analysis.
2.4 - Feature Normalization¶
The features we will work with can be categorized as follows:
Numerical Features: (includes both continuous and discrete variables)
- Age
- log10SplitFare
- Parch
- SibSp
- FamilySize
- GroupSize
Ordinal Categorical Features: (Categorical features that can be ordered)
- AgeBin
- Pclass
Nominal Categorical Features: (Categorical features that don't imply any order)
- Sex
- Embarked
- IsChild
- LargeGroup
- GroupType
- IsGG
There are generally two normalization steps we must take to prepare our data for handling by machine learning models:
We must map all categorical strings to integers. For ordinal features, we must ensure this integer mapping sorted in a sensible way; for nominal features, we typically separate each feature into a set of orthogonal unit vectors with each vector representing one of the possible categories for that feature (called one-hot encoding).
We should perform feature scaling, for example by standardizing our data so that our feature values are centered at mean zero with a standard deviation of unity. Most machine learning optimization algorithms perform better if features are on the same scale. For an intuitive picture of why, suppose Feature-1 ranges from 0.0 to 100.0 while Feature-2 ranges from 0.0-1.0; the optimization algorithm will tend to see larger errors for Feature-1 and hence will focus much more on minimizing Feature-1 errors compared to Feature-2 errors. Bringing features onto the same scale helps facilitate more balanced optimization, and smaller feature ranges tend to help keep the feature weights small.
a) Converting Categorical Strings to Numbers¶
For our ordinal variables, this process is straightforward. Pclass is already numerical and sorted. For AgeBin we'll apply a map:
# mapping of AgeBin to integer value
ageBin_to_integer = {'0-15': 1,
'16-29': 2,
'30-40': 3,
'41-59': 4,
'60+': 5}
dataset['AgeBin'] = dataset['AgeBin'].map(ageBin_to_integer)
Sex, IsChild, LargeGroup, and IsGG are all binary features, with the latter three already being appropriately mapped. For Sex, we'll map 'male' to 0, and 'female' to 1:
dataset['Sex'] = dataset['Sex'].map({'male': 0, 'female': 1})
For Embarked and GroupType, we can conveniently create binary 'dummy features' via one-hot encoding using panda's get_dummies() method. If applied to an entire dataframe, this will only act upon string columns. We will also create a copy of our data, called 'dataset_cleaned', from which we will begin to drop unwanted features.
# *** First let's do some housecleaning and drop the features we won't be working with ***
# create a list of all the column headers in our dataframe
full_feature_list = list(dataset.columns.values)
# specify only the features we are working with
working_feature_list = ['Age', 'log10SplitFare', 'Parch', 'SibSp', 'FamilySize', 'GroupSize',
'AgeBin', 'Pclass', 'Sex', 'Embarked', 'IsChild', 'LargeGroup', 'GroupType', 'IsGG']
# we'll also keep Name, PassengerId and our class-label 'Survived' of course
# so let's generate the list of all features we will drop:
dropped_feature_list = list(set(full_feature_list) -
set(working_feature_list + ['Name', 'PassengerId', 'Survived']))
# now let's create the 'cleaned' dataset
dataset_cleaned = dataset.copy()
dataset_cleaned = dataset_cleaned.drop(dropped_feature_list, axis=1)
print('\nThe dropped features were:', dropped_feature_list)
# *** Next let's apply one-hot encoding to the remaining string columns (Embarked and GroupType) ***
# return dataset with new dummy variables added
dataset_cleaned = pd.get_dummies(dataset_cleaned, columns=['Embarked', 'GroupType'])
# update the list of features we are working with
working_feature_list = list(dataset_cleaned.columns.values)
print('\nThe updated list of columns in our dataset are:', working_feature_list)
# let's save a copy of this 'cleaned dataset
dataset_cleaned.to_csv('./titanic-data/cleaned_dataset.csv')
As we can see, 'Embarked' was separated into 'Embarked_C', 'Embarked_Q', 'Embarked_S'... and similarly for GroupType. Let's have a quick look to see these changes to our dataframe:
feature_list = ['PassengerId', 'GroupType_IsAlone', 'GroupType_Mixed', 'GroupType_Family', 'GroupType_NonFamily',
'Embarked_C', 'Embarked_Q', 'Embarked_S']
dataset_cleaned[feature_list].head(5)
b) Feature Scaling¶
With one-hot encoding, all of our nominal categorical features are already normalized to the range [0,1]. For our ordinal and continuous-variable features, we choose to apply standardization. For this we use the sklearn library's StandardScaler:
standardized_feature_list =['Age', 'log10SplitFare', 'Parch', 'SibSp', 'FamilySize',
'GroupSize', 'AgeBin', 'Pclass']
dataset_cleaned_std = dataset_cleaned.copy()
scaler = StandardScaler() # create instance of scikit-learn's StandardScalar object
# simultaneously fit the StandardScalar object and transform the selected features:
dataset_cleaned_std[standardized_feature_list] = scaler.fit_transform(
dataset_cleaned_std[standardized_feature_list].values)
Let's take a quick look at the results of our feature standardization:
axes = dataset_cleaned_std.boxplot(column=standardized_feature_list,
rot=90, figsize=(12,5), return_type='axes')
g = axes.set_ylim(-4.0, 4.0)
g = axes.set_ylabel('Standardized Value')

Note: the reason for the odd appearance of the Parch boxplot is merely that the boundaries of the first, second, and third quartiles all have the same value, since we have Parch=0 for more than 75% of all instances (prior to standardization). See below:
print('Fractional Distribution of Unscaled Parch Values:')
print(dataset_cleaned.Parch.value_counts(normalize=True))
We can also double-check our standardization using panda's built-in describe() method:
dataset_cleaned_std[standardized_feature_list].describe().loc[['mean', 'std', 'min', 'max']]
The means are indeed zero and the standard deviations are near unity, as we'd like.
3) Feature Selection and Dimensionality Reduction¶
In the previous two sections, we explored our data, defined new features, and prepared our features for input into machine learning algorithms. In this section, our aim is to identify feature subsets that will allow us to obtain good predictive accuracy without 'overfitting' our model. A model that is 'overfit' generalizes poorly to unseen data. This tends to happen when too many features are included, and is colloquially known as the "curse of dimensionality".
We will examine three approaches to selecting a feature subset:
- Recursive Feature Elimination (RFE) on our full feature set.
- Principal Component Analysis (PCA) on our full feature set.
- Feature selection based solely on our Exploratory Data Analysis.
To be able to assess feature importance, we'll need to define some classifiers. Typically, one might want to iterate between feature selection and classifier optimization -- it depends on one's available time budget for maximizing classification performance. Obtaining the best-performing classifier could take weeks of experimenting with different features, algorithms, and hyperparameters. Here we'll focus on the feature selection first, and won't worry about hyperparameter optimization until Section 4. The classification algorithms we choose to work with will include:
- Logistic Regression
- Stochastic Gradient Descent (SGD)
- Decision Trees
- Random Forests
- Linear Discriminant Analysis (LDA)
- Support Vector Machines (SVM)
- Gradient Boosting
- Extreme Gradient Boosting (XGB)
- AdaBoost
We won't cover the details here of how each of these algorithms work. However, there are a plethora of resources available online discussing their formulation and implementation. Conveniently, many of these classification methods are now part of the scikit-learn library, so you can check out scikit-learn's documentation for more details. More information about the increasingly-popular XGBoost algorithm can be found here.
3.1 - Getting Started¶
Let's define the full list of features we'll be starting with. Our goal is to eliminate features from this list that provide little advantage to our classification task.
training_feature_list = ['Age',
'Parch',
'Pclass',
'Sex',
'SibSp',
'FamilySize',
'IsChild',
'GroupSize',
'AgeBin',
'log10SplitFare',
'LargeGroup',
'IsGG',
'Embarked_C',
'Embarked_Q',
'Embarked_S',
'GroupType_Family',
'GroupType_IsAlone',
'GroupType_Mixed',
'GroupType_NonFamily']
We now also separate our data into its 'train' and 'test' components. Remember here that the 'test' entries are ones for which we lack information about survival. It will also be convenient to split the features and class labels into separate arrays (X and y, respectively).
# separate into cleaned, standardized test and training subsets
data_test_cl_std = dataset_cleaned_std[dataset_cleaned_std.PassengerId.isin(test_Ids)]
data_train_cl_std = dataset_cleaned_std[~dataset_cleaned_std.PassengerId.isin(test_Ids)]
# note: tidle (~) in above line denotes logical not
# we will also further subdivide into a feature dataframe (X) a class dataframe (y, for 'Survived')
X_train = data_train_cl_std[training_feature_list]
y_train = data_train_cl_std['Survived']
ids_train = data_train_cl_std['PassengerId']
X_test = data_test_cl_std[training_feature_list]
ids_test = data_test_cl_std['PassengerId']
Now we'll define some useful functions, including one that fits input classifiers on our training data and returns cross-validated accuracies. I choose to use Stratified K-fold Cross-Validation. In the specific instance below, I manually tabulate the scores for each fold instead of using scikit-learn's cross_val_score function because I also want to compute mean feature importances, which cross_val_score doesn't provide. You can read more about the importance of cross-validation and its implementation here.
def get_clf_name(classifier_object):
"""
Returns a string representing the name of the input classifier object.
"""
name_ = str(type(classifier_object)).split('.')[-1]
for char in """ "'>() """: # triple-quoted string definition allows us to include " and ' as characters
name_ = name_.replace(char,"") # delete unwanted characters from the name
return name_
def train_classifier_ensemble_CV(classifiers, X_data, y_data, clf_params=None, cv_splits=10,
random_state=27, return_trained_classifiers=False, verbose=0):
"""
Trains a list of classifiers on the input training data and returns cross-validated accuracy and f1 scores
as well as feature_importances (where available). The list of trained classifier objects is also returned
upon request.
: param classifiers : List of classifier objects; expects each has a scikit-learn wrapper.
: param X_data : Pandas dataframe containing our training features.
: param y_data : Pandas dataframe containing our training class labels.
: param clf_params : (Optional) List of dictionaries containing parameters for each classifier object
in the list 'classifiers'. If not provided, the already-initialized parameters of
each classifier object will be used.
: param cv_splits : Integer number of cross-validation splits.
: param random_state : Seed for reproducibility between executions.
: param return_trained_classifiers : Boolean; if True, function will also return a list containing the
fit classifier objects.
: param verbose : The amount of status text displayed during execution; 0 for less, 1 for more.
: return clf_comparison : A pandas dataframe tabulating the cross-validated performance of each classifier.
: return mean_feature_importances : An array containing the ranked feature importances for each classifier
having the feature_importances_ attribute.
: return trained_classifiers : (if return_trained_classifiers=True) A list of trained classifier objects.
"""
# initialization
kfold = StratifiedKFold(n_splits=cv_splits, random_state=random_state)
train_accuracy_mean = []
train_accuracy_std = []
test_accuracy_mean = []
test_accuracy_std = []
f1_score_mean = []
f1_score_std = []
mean_feature_importances = []
trained_classifiers = []
classifier_name = []
if clf_params is None: # construct using classifier's existing parameter assignment
clf_params = []
for clf in classifiers:
params = clf.get_params()
if 'random_state' in params.keys(): # assign random state / seed
params['random_state'] = random_state
elif 'seed' in params.keys():
params['seed'] = random_state
clf_params.append(params)
# step through the classifiers for training and scoring with cross-validation
for clf, params in zip(classifiers, clf_params):
# automatically obtain the name of the classifier
name = get_clf_name(clf)
classifier_name.append(name)
if verbose == 1: # print status
print('\nPerforming Cross-Validation on Classifier %s of %s:'
% (len(classifier_name), len(classifiers)))
print(name)
# perform k-fold cross validation for this classifier and calculate scores for each split
kth_train_accuracy = []
kth_test_accuracy = []
kth_test_f1_score = []
kth_feature_importances = []
for (train, test) in kfold.split(X_data, y_data):
clf.set_params(**params)
clf.fit(X_data.iloc[train], y_data.iloc[train])
kth_train_accuracy.append(clf.score(X_data.iloc[train], y_data.iloc[train]))
kth_test_accuracy.append(clf.score(X_data.iloc[test], y_data.iloc[test]))
kth_test_f1_score.append(f1_score(y_true=y_data.iloc[test], y_pred=clf.predict(X_data.iloc[test])))
if hasattr(clf, 'feature_importances_'): # some classifiers (like linReg) lack this attribute
kth_feature_importances.append(clf.feature_importances_)
# populate scoring statistics for this classifier (over all cross-validation splits)
train_accuracy_mean.append(np.mean(kth_train_accuracy))
train_accuracy_std.append(np.std(kth_train_accuracy))
test_accuracy_mean.append(np.mean(kth_test_accuracy))
test_accuracy_std.append(np.std(kth_test_accuracy))
f1_score_mean.append(np.mean(kth_test_f1_score))
f1_score_std.append(np.std(kth_test_f1_score))
# obtain array of mean feature importances, if this classifier had that attribute
if len(kth_feature_importances) == 0:
mean_feature_importances.append(False)
else:
mean_feature_importances.append(np.mean(kth_feature_importances, axis=0))
# if requested, also export classifier after fitting on the complete training set
if return_trained_classifiers is not False:
clf.fit(X_data, y_data)
trained_classifiers.append(clf)
# remove AdaBoost feature importances (we won't discuss their interpretation)
if type(clf) == type(AdaBoostClassifier()):
mean_feature_importances[-1] = False
# construct dataframe for comparison of classifiers
clf_comparison = pd.DataFrame({'Classifier Name' : classifier_name,
'Mean Train Accuracy' : train_accuracy_mean,
'Train Accuracy Standard Deviation' : train_accuracy_std,
'Mean Test Accuracy' : test_accuracy_mean,
'Test Accuracy Standard Deviation' : test_accuracy_std,
'Mean Test F1-Score' : f1_score_mean,
'F1-Score Standard Deviation' : f1_score_std})
# enforce the desired column order
clf_comparison = clf_comparison[['Classifier Name', 'Mean Train Accuracy',
'Train Accuracy Standard Deviation', 'Mean Test Accuracy',
'Test Accuracy Standard Deviation', 'Mean Test F1-Score',
'F1-Score Standard Deviation']]
# add return_trained_classifiers to the function return, if requested, otherwise omit
if return_trained_classifiers is not False:
return clf_comparison, mean_feature_importances, trained_classifiers
else:
return clf_comparison, mean_feature_importances
def plot_mean_feature_importances(clf_comparison, mean_feature_importances, X_data):
"""
Generates bar plots of feature importances using the results of train_classifier_ensemble_CV.
: param clf_comparison : A pandas dataframe comparing cross-validated classifier performances;
one of the return parameters of the train_classifier_ensemble_CV function.
: param mean_feature_importances : An array of feature importances, generated by the
train_classifier_ensemble_CV function.
: param X_data : A pandas dataframe of the feature data used in the creation of clf_comparison and
mean_feature_importances.
: return : None.
"""
for clf_name, importances in zip(clf_comparison['Classifier Name'], mean_feature_importances):
if importances is not False:
indices = np.argsort(importances)[::-1]
feature_labels = X_data.columns
plt.figure(figsize=(12,5))
plt.title('Feature Importances for ' + clf_name)
plt.bar(range(X_data.shape[1]), importances[indices], color='lightblue', align='center')
plt.xticks(range(X_data.shape[1]), feature_labels[indices], rotation=90)
plt.xlim([-1, X_data.shape[1]])
plt.tight_layout()
plt.show()
return
3.2 - Initial Performance on Full Feature Set¶
As a benchmark, let's first train our classifiers on the full feature set. At the same time, we can extract some of the feature importances as ranked by some of our tree- or ensemble-based classifiers.
We'll define our list of classifiers as follows, where we specify some (but not all) of their hyperparameters (we will perform optimization later in Section 4):
num_jobs=-1 # I'll use all available CPUs when possible
classifier_list = [LogisticRegression(n_jobs=num_jobs),
SGDClassifier(alpha=0.01, n_jobs=num_jobs),
DecisionTreeClassifier(),
ExtraTreeClassifier(max_depth=5, min_samples_split=10, splitter='random'),
RandomForestClassifier(n_estimators=100, n_jobs=num_jobs),
LinearDiscriminantAnalysis(n_components=5, solver='svd'),
SVC(shrinking=True, kernel='rbf'),
XGBClassifier(booster='gbtree', n_jobs=num_jobs),
GradientBoostingClassifier(n_estimators=100, loss='deviance'),
AdaBoostClassifier(DecisionTreeClassifier(), n_estimators=50)]
Now let's train our classifiers using the full feature set:
clf_comp_Full_FeatureSet, mean_feature_importances = train_classifier_ensemble_CV(classifiers=classifier_list,
X_data=X_train,
y_data=y_train)
# display the comparison results
clf_comp_Full_FeatureSet
Most of our untuned classifiers are showing around 80% test accuracy. Note however, that for many, the training accuracy is much higher than the test accuracy, which is a sign of overfitting. In particular, the Decision Tree, Random Forest, XBG, Gradient Boosting, and AdaBoost classifiers all suffer from a high degree of overfitting. For example, AdaBoost and is showing 98% training accuracy but only 79% testing accuracy. Reduction in the number of features, as well as hyperparameter tuning later, should be able to reduce this discrepency to achieve a better 'bias-variance tradeoff', i.e. an optimum between prediction accuracy and overfitting.
3.3 - Feature Importances of our Tree and Ensemble Classifiers¶
We can examine how some of the classifiers we just trained ranked feature importance:
plot_mean_feature_importances(clf_comp_Full_FeatureSet, mean_feature_importances, X_data=X_train)





Findings:
- Sex is the top feature for 3/5 of these classifiers.
- Log10SplitFare and Age also rank highly.
- GroupSize generally ranked within the top 5 features.
- The importance of Pclass is ranked fairly low, but this might be due to Log10SplitFare serving as a substitute that conveys essentially the same information.
3.4 - Dimensionality Reduction via Recursive Feature Elimination (RFE)¶
Now we will perform Recursive Feature Elimination (RFE) to assess feature importance by iteratively removing features to see which have the least impact on classifier performance. First we define a function that implements RFE with the help of scikit-learn:
def get_RFE_rankings(classifiers, X_data, y_data, verbose=0):
"""
Performs recursive feature elimination and returns feature rankings for each classifier.
: param classifiers : List of classifiers objects; assumed to have scikit-learn wrappers.
: param X_data : Pandas dataframe containing our full feature training set.
: param y_data : Pandas dataframe containing our training class labels.
: param verbose: Int, controls amount of status-based text displayed; 1 for more, 0 for less.
: return feature_rankings : Pandas dataframe tabulating ranked feature importance for each classifier.
"""
feature_rankings = pd.DataFrame()
feature_rankings['Feature Name'] = X_data.columns
for clf in classifiers:
# get classifier name
name = str(type(clf)).split('.')[-1]
for char in """ "'>() """: # triple-quoted string definition allows us to include " and ' as characters
name = name.replace(char,"") # delete unwanted characters from the name
if name == 'SVC': # SVC does not expose "coef_" or "feature_importances_" attributes, so skip it
print('Skipped RFE for SVC')
continue
if name == 'AdaBoostClassifier': # this classifier causes an error to be thrown with RFE
print('Skipped RFE for AdaBoostClassifier')
continue
# print status if requested
if verbose == 1:
print('Now performing RFE for', name)
# get freature ranking
rfe = RFE(estimator=clf, n_features_to_select=1, step=1)
rfe.fit(X_data, y_data)
# save as new column in dataframe
feature_rankings[name] = rfe.ranking_
# now sum up totals to obtain an overall ranking
# (each classifier's feature ranking will be equally weighted)
summed_rankings = feature_rankings.sum(axis=1)
# here we turn the sum into a rank (lower rank goes with lower sum)
sorted_rankings = [0] * len(summed_rankings)
for i, x in enumerate(sorted(range(len(summed_rankings)), key=lambda y: summed_rankings[y])):
sorted_rankings[x] = i + 1 # offset so that lowest rank is 1
feature_rankings['Overall Ranking'] = sorted_rankings
# re-order dataframe so that 'Overall Ranking' is the 2nd column
cols = feature_rankings.columns.tolist()
cols = [cols[0]] + [cols[-1]] + cols[1:-1]
feature_rankings = feature_rankings[cols]
# sort the dataframe rows in terms of acending rank
feature_rankings = feature_rankings.sort_values(by='Overall Ranking')
return feature_rankings
We now execute the RFE function:
feature_rankings_RFE = get_RFE_rankings(classifiers=classifier_list, X_data=X_train, y_data=y_train, verbose=1)
feature_rankings_RFE
The features in the above table have been sorted based on their overall ranking, which aggregates the results for each classifier. How many of these top features should we include? We can iterate over our train_classifier_ensemble_CV() function to find out:
pooled_train_accuracies = []
pooled_test_accuracies = []
# we'll start with the top 10 features and then iteratively drop the least important one
for num_features in range(10, 0, -1):
print('Computing for top %s feature(s)...' % num_features)
kept_features = feature_rankings_RFE['Feature Name'].iloc[:num_features]
X_train_reduced = X_train[kept_features].copy()
clf_comparison, _ = train_classifier_ensemble_CV(classifiers=classifier_list,
X_data=X_train_reduced,
y_data=y_train)
pooled_train_accuracies.append(clf_comparison['Mean Train Accuracy'].mean())
pooled_test_accuracies.append(clf_comparison['Mean Test Accuracy'].mean())
print('*** Complete ***')
Now let's plot the results:
plt.figure(figsize=(7, 5))
plt.plot(range(10, 0, -1), pooled_train_accuracies, color='blue', marker='o', markersize=5, label='Training Accuracy')
plt.plot(range(10, 0, -1), pooled_test_accuracies, color='green', linestyle='--', marker='s', markersize=5, label='Test Accuracy')
plt.xlabel('Number of Top Features Kept')
plt.ylabel('Pooled Accuracy')
plt.legend(loc=4)
plt.ylim([0.7, 0.9])
plt.xticks(range(10, 0, -1))
plt.show()

In computing the above, we've taken the average accuracy across all classifiers. This is somewhat crude; it might be more representative if we based our accuracy on a majority vote across all classifiers. In any case, our approach here shows that 8 features is the optimal number to keep. Beyond this, the pooled test accuracy begins to decrease. Note that we still have a significant discrepency between training and test accuracies. To improve bias-variance tradeoff further, we might need to iterate over the number of included features together with the classifier hyperparameters. We'll explore this later. For now, let's define our resultant RFE feature subset and obtain our classification performance results:
feature_subset_RFE = feature_rankings_RFE['Feature Name'].iloc[:8]
clf_comp_RFE_FeatureSet, _ = train_classifier_ensemble_CV(classifiers=classifier_list,
X_data=X_train[feature_subset_RFE],
y_data=y_train)
# display the comparison results
clf_comp_RFE_FeatureSet
3.5 - Dimensionality Reduction via Principal Component Analysis (PCA)¶
We now use a powerful unsupervised technique called Principal Component Analysis (PCA). In short, PCA looks at correlations in your features to define a new set of axes corresponding to the directions of maximum variance. The idea is that these directions of maximum variance, which are linear combinations of correlated features from our original feature space, contain most of the interesting information (or 'signal') useful for classification. We thus reduce dimensionality by creating a new feature space that is a linear combination of the old that retains most of the information while dropping the least important axes.
Performing PCA on the complete dataset:
# performing PCA and retain the top 12 principal components:
from sklearn.decomposition import PCA
pca = PCA(n_components=12)
X_train_pca = pca.fit_transform(X_train)
pca_components = pca.components_
pca_var_ratios = pca.explained_variance_ratio_
plt.figure(figsize=(15, 8))
plt.bar(range(1, pca_var_ratios.size +1), pca_var_ratios, align='center', label='individual explained variance')
plt.step(range(1, pca_var_ratios.size +1), np.cumsum(pca_var_ratios), where='mid', label='cumulative explained variance')
plt.ylabel('Explained Variance Ratio')
plt.xlabel('Principal Components')
plt.xticks(range(1, pca_var_ratios.size +1))
plt.legend(loc='best')
plt.show()

We find that more than 80% of the variance is explained by the top 4 principal components.
It is interesting to see which of our original feature vectors are part of these top 4 prinicipal components. We can do this by computing the squared magnitudes of the projections of our original feature vectors onto these principal component vectors. Note that the amplitudes of the projections are stored in pca_components.
f, axarr = plt.subplots(4, sharex=True, figsize=(15,8))
f.subplots_adjust(left=None, bottom=None, right=None, top=None, hspace=0.25)
axarr[0].bar(range(1, pca_components[0].size + 1), pca_components[0]**2,
align='center', label='PC1')
axarr[0].legend(loc='best')
axarr[1].bar(range(1, pca_components[1].size + 1), pca_components[1]**2,
align='center', label='PC2', color='r')
axarr[1].legend(loc='best')
axarr[2].bar(range(1, pca_components[2].size + 1), pca_components[2]**2,
align='center', label='PC3', color='g')
axarr[2].legend(loc='best')
axarr[3].bar(range(1, pca_components[3].size + 1), pca_components[3]**2,
align='center', label='PC4', color='m')
axarr[3].legend(loc='best')
plt.xticks(np.arange(1.0, pca_components[0].size +1.0), X_train.columns, rotation=90)
plt.suptitle('Weighting of Feature Combinations Yielding Top 4 Principal Components', y=0.92)
plt.show()

Comments:
- PC1 is combining features related to age and the number of family members.
- PC2 appears to be capturing information that correlates between Pclass, Age, and Fare, but with a few other features related to family mixed in.
- PC3 is also focused on Pclass, Age, and Fare, but with less contribution from family size.
- PC4 appears to be focused entirely on Parch and SibSp, and thus FamilySize.
One interesting omission from our top 4 principal components is Sex. We know this to be an important feature from our Exploratory Data Analysis. But perhaps its low correlation with other features causes it to be omitted.
So what are the principal components for which Sex has a significant contribution? We can easily investigate this below:
print('Principal Components Ranked by Projection onto Feature Axes')
for i, feature_ in enumerate(X_train.columns):
print(feature_, ':', (pca_components[:, i]**2).argsort()[-pca_components.shape[1]:][::-1])
We see that Sex doesn't make a major contribution until around principal component 5.
Let's now train our classifiers on the PCA-transformed data and determine the optimal number of PCA components to keep. We'll first define two helpful functions:
def get_optimal_n_components(clf, X_data_pca, y_data, cv_splits=10,
random_state=27, plot_scores=False):
"""
Trains a classifier on input principal component data, iteratively dropping the least significant
component to determine the number of components yielding the highest cross-validated scores (accuracy
and f1-score).
Assumes classifier parameters are already initialized.
: param clf : Classifier object, assumed to have a scikit-learn wrapper.
: param X_data_pca : Array of training data in principal component space, arranged from most significant
to least significant principal component.
: param y_data : Vector of class labels corresponding to the training data.
: param cv_splits : Integer number of cross-validation splits.
: param random_state : Seed for reproducability.
: param plot_scores : Boolean, if True the accuracy and f1-scores will be plotted as a function of the
number of kept principal components.
: return results_dict: Python dictionary containing the best-achieved scores and the corresponding
number of kept principal components.
"""
num_dropped_components = np.arange(1, X_data_pca.shape[1])
mean_accuracies = []
mean_f1scores = []
# compute cross-validated accuracies and f1-scores after dropping n components
kfold = StratifiedKFold(n_splits=cv_splits, random_state=random_state)
for n_dropped in num_dropped_components:
accuracy_scores = cross_val_score(clf, X_data_pca[:, 0:-n_dropped], y_data,
cv=kfold, scoring='accuracy')
f1_scores = cross_val_score(clf, X_data_pca[:, 0:-n_dropped], y_data,
cv=kfold, scoring='f1_macro')
mean_accuracies.append(accuracy_scores.mean())
mean_f1scores.append(f1_scores.mean())
# obtain and return the best results
index_best_accuracy = np.argmax(mean_accuracies)
index_best_f1score = np.argmax(mean_f1scores)
results_dict = {'best_accuracy' : mean_accuracies[index_best_accuracy],
'best_accuracy_n' : X_data_pca.shape[1] - num_dropped_components[index_best_accuracy],
'best_f1score' : mean_f1scores[index_best_f1score],
'best_f1score_n' : X_data_pca.shape[1] - num_dropped_components[index_best_f1score]
}
# plot the scores if requested
if plot_scores is not False:
plt.figure(figsize=(14,5))
plt.plot(X_data_pca.shape[1] - num_dropped_components, mean_accuracies, label='Accuracy')
plt.plot(X_data_pca.shape[1] - num_dropped_components, mean_f1scores, label='F1-Score')
plt.xticks(X_data_pca.shape[1] - num_dropped_components)
plt.xlabel('Number of Principal Components')
plt.ylabel('Score')
plt.legend(loc='best')
plt.title(get_clf_name(clf))
plt.show()
return results_dict
def compare_optimal_n_components(classifiers, X_data_pca, y_data, clf_params=None,
cv_splits=10, random_state=27, verbose=0, plot_scores=False):
"""
Obtains and tabulates the optimal number of principal components and corresponding best cross-validated
test scores for a list of classifier objects.
: param classifiers : List of classifier objects, assumed to have scikit-learn wrappers.
: param X_data_pca : Array of training data in principal component space, arranged from most significant
to least significant principal component.
: param y_data : Vector of class labels corresponding to the training data.
: param clf_params : Optional list of dictionaries stating the classifier parameters to be used. If not
provided, then we use the parameters already initialized for the classifier objects.
: param cv_splits : Integer number of cross-validation splits.
: param random_state : Seed for reproducability.
: param plot_scores : Boolean, if True the accuracy and f1-scores will be plotted as a function of the
number of kept principal components.
: return comparison : Pandas dataframe tabulating the best scores and optimal number of principal
components for each classifier object in 'classifiers'.
"""
# initialization
clf_names = []
best_accuracy = []
best_accuracy_n_components = []
best_f1score = []
best_f1score_n_components = []
if clf_params is None: # construct using classifier's existing parameter assignment
clf_params = []
for clf in classifiers:
params = clf.get_params()
if 'random_state' in params.keys(): # assign random state / seed
params['random_state'] = random_state
elif 'seed' in params.keys():
params['seed'] = random_state
clf_params.append(params)
# step through the classifiers
for clf, params in zip(classifiers, clf_params):
clf.set_params(**params)
classifier_name = get_clf_name(clf)
clf_names.append(classifier_name)
if verbose == 1: # print status
print('\nFinding Optimal Number of Principal Components for Classifier %s of %s:'
% (len(clf_names), len(classifiers)))
print(classifier_name)
# find optimal number of principal components using cross-validated scoring,
# and return their scores (both accuracy and f1-score)
results = get_optimal_n_components(clf, X_data_pca, y_data,
cv_splits=10, random_state=random_state,
plot_scores=plot_scores)
best_accuracy.append(results['best_accuracy'])
best_accuracy_n_components.append(results['best_accuracy_n'])
best_f1score.append(results['best_f1score'])
best_f1score_n_components.append(results['best_f1score_n'])
# create dataframe for comparing results
comparison = pd.DataFrame(columns=['Classifier',
'Best Accuracy',
'Num Components (Best Accuracy)',
'Best F1-Score',
'Num Components (Best F1-Score)'])
comparison['Classifier'] = clf_names
comparison['Best Accuracy'] = best_accuracy
comparison['Num Components (Best Accuracy)'] = best_accuracy_n_components
comparison['Best F1-Score'] = best_f1score
comparison['Num Components (Best F1-Score)'] = best_f1score_n_components
return comparison
Now performing the computation. We'll use only 5 cross-validation splits, due to relatively long computation time. We'll also plot test scores for each classifier.
comparison_PCA = compare_optimal_n_components(classifier_list, X_train_pca, y_train,
cv_splits=5, random_state=27, verbose=1,
plot_scores=True)
comparison_PCA










Findings:
- On average, our classifiers perform best when we keep 9 principal components.
Comments:
- The f1-scores follow the accuracy scores. We haven't discussed f1-scores much here (they are essentially the harmonic mean of precision and recall), but in some cases they can provide a better indication of classifier performance. Since the f1-score behaviour just mirrors that of the accuracy in our case, we won't concern ourselves with it any further.
- The LogisticRegression, SCV, LinearDiscriminant, and SGD classifiers all seem to go flat around 3-6 principal components, before their scores begin increasing again. Note that we found the 'Sex' feature to kick in at around principal component 5.
Finally, let's define the PCA feature subset and calculate the associated classifier scores:
X_train_PCA_subset = pd.DataFrame(X_train_pca[:, :9])
clf_comp_PCA_FeatureSet, _ = train_classifier_ensemble_CV(classifiers=classifier_list,
X_data=X_train_PCA_subset,
y_data=y_train)
# display the comparison results
clf_comp_PCA_FeatureSet
3.6 - Selecting a Feature Subset Based on our Exploratory Data Analysis¶
Here we leverage our findings from Exploratory Data Analysis in an attempt to assemble the simplest subset of features providing accurate prediction. The most important features we identified (see discussion in Section 1.5) were:
- Sex
- Pclass
- AgeBin (or Age)
- LargeGroup (or Parch)
We have a few possible substitutions (Age for AgeBin, Parch for LargeGroup) that we can try. Let's find the combination that gives the highest pooled test accuracy:
f_set_1 = ['Sex', 'Pclass', 'AgeBin', 'LargeGroup']
f_set_2 = ['Sex', 'Pclass', 'AgeBin', 'Parch']
f_set_3 = ['Sex', 'Pclass', 'Age', 'LargeGroup']
f_set_4 = ['Sex', 'Pclass', 'Age', 'Parch']
pooled_test_accuracies = []
for i, feature_set in enumerate([f_set_1, f_set_2, f_set_3, f_set_4], 1):
clf_comparison, _ = train_classifier_ensemble_CV(classifiers=classifier_list,
X_data=X_train[feature_set],
y_data=y_train)
pooled_test_accuracies.append(clf_comparison['Mean Test Accuracy'].mean())
print('Pooled Test Accuracy for Feature Set %s: %.2f' % (i, pooled_test_accuracies[-1]))
So we'll use feature subset 1. Let's obtain the cross-validated classifier performances:
feature_subset_EDA = ['Sex', 'Pclass', 'AgeBin', 'LargeGroup']
clf_comp_EDA_FeatureSet, _ = train_classifier_ensemble_CV(classifiers=classifier_list,
X_data=X_train[feature_subset_EDA],
y_data=y_train)
# display the comparison results
clf_comp_EDA_FeatureSet
Findings:
- Our mean train and test accuracies are similar, showing that this feature set achieves a superior bias-variance tradeoff compared to our other feature subsets, and therefore should have better generalization performance.
- The test accuracies are higher than what we obtained for PCA feature reduction, and are comparable to what was achieved using RFE.
3.7 - Summary and Initial Comparison of Feature Subsets¶
Finally, let's compare the performance of our trained but yet-to-be-optimized classifiers as yielded by each of our feature sets:
# plot the mean cross-validated test accuracies for each feature subset:
matplotlib.style.use('default')
matplotlib.rcParams.update({'font.size': 22})
fig, ax = plt.subplots(figsize=(15,20))
width = 0.20
y_position = np.arange(1, clf_comp_Full_FeatureSet['Classifier Name'].shape[0] + 1)
ax.barh(y_position, clf_comp_Full_FeatureSet['Mean Test Accuracy'], width,
xerr=clf_comp_Full_FeatureSet['Test Accuracy Standard Deviation'],
align='center', ecolor='black', label='Full Feature Set')
ax.barh(y_position + width, clf_comp_RFE_FeatureSet['Mean Test Accuracy'], width,
xerr=clf_comp_RFE_FeatureSet['Test Accuracy Standard Deviation'],
align='center', ecolor='black', label='RFE Feature Subset')
ax.barh(y_position + 2*width, clf_comp_PCA_FeatureSet['Mean Test Accuracy'], width,
xerr=clf_comp_PCA_FeatureSet['Test Accuracy Standard Deviation'],
align='center', ecolor='black', label='PCA Feature Subset')
ax.barh(y_position + 3*width, clf_comp_EDA_FeatureSet['Mean Test Accuracy'], width,
xerr=clf_comp_EDA_FeatureSet['Test Accuracy Standard Deviation'],
align='center', ecolor='black', label='EDA Feature Subset')
ax.set_xlim([0.5, 1.0])
ax.set_xlabel('Cross-Validated Test Accuracy', fontweight='bold')
ax.set_yticks(y_position + 1.5*width)
ax.set_yticklabels(clf_comp_Full_FeatureSet['Classifier Name'].values)
ax.set_ylabel('Classifier Name', fontweight='bold')
ax.legend(loc=9, bbox_to_anchor=(1.0, 1.0))
plt.show()

Findings:
- The EDA Feature Subset yields the highest accuracies for the AdaBoost, SVC, RandomForest, ExtraTree, DecisionTree, and LogisticRegression classifiers.
- The RFE Feature Subset yields the highest accuracies for the GradientBoosting, XGB, and SGD classifiers.
- The PCA Feature Subset yields the lowest accuracy for almost every classifier.
We can also get an idea of overall performance by comparing the pooled accuracies (averaged over all classifiers):
print('Full Feature Set Pooled Test Accuracy: %.3f' % clf_comp_Full_FeatureSet['Mean Test Accuracy'].mean())
print('RFE Feature Subset Pooled Test Accuracy: %.3f' % clf_comp_RFE_FeatureSet['Mean Test Accuracy'].mean())
print('PCA Feature Subset Pooled Test Accuracy: %.3f' % clf_comp_PCA_FeatureSet['Mean Test Accuracy'].mean())
print('EDA Feature Subset Pooled Test Accuracy: %.3f' % clf_comp_EDA_FeatureSet['Mean Test Accuracy'].mean())
So we see that the EDA feature subset gives the overall best accuracy, with the RFE subset following close behind.
But test accuracy isn't the whole picture. We also want good generalization performance. So now let's consider the absolute difference between the training and test accuracies. This gives us an idea of the bias-variance trade-off, where a higher absolute difference implies greater overfitting and therefore poorer generalization performance:
matplotlib.style.use('default')
matplotlib.rcParams.update({'font.size': 22})
fig, ax = plt.subplots(figsize=(15,20))
width = 0.20
y_position = np.arange(1, clf_comp_Full_FeatureSet['Classifier Name'].shape[0] + 1)
diffs_Full_set = abs(clf_comp_Full_FeatureSet['Mean Test Accuracy'] -
clf_comp_Full_FeatureSet['Mean Train Accuracy'])
ax.barh(y_position, diffs_Full_set, width, align='center', ecolor='black', label='Full Feature Set')
diffs_RFE_set = abs(clf_comp_RFE_FeatureSet['Mean Test Accuracy'] -
clf_comp_RFE_FeatureSet['Mean Train Accuracy'])
ax.barh(y_position + width, diffs_RFE_set, width,
align='center', ecolor='black', label='RFE Feature Subset')
diffs_PCA_set = abs(clf_comp_PCA_FeatureSet['Mean Test Accuracy'] -
clf_comp_PCA_FeatureSet['Mean Train Accuracy'])
ax.barh(y_position + 2*width, diffs_PCA_set, width,
align='center', ecolor='black', label='PCA Feature Subset')
diffs_EDA_set = abs(clf_comp_EDA_FeatureSet['Mean Test Accuracy'] -
clf_comp_EDA_FeatureSet['Mean Train Accuracy'])
ax.barh(y_position + 3*width, diffs_EDA_set, width,
align='center', ecolor='black', label='EDA Feature Subset')
ax.set_xlabel('Magnitude of Test-Train Accuracy Difference', fontweight='bold')
ax.set_yticks(y_position + 1.5*width)
ax.set_yticklabels(clf_comp_Full_FeatureSet['Classifier Name'].values)
ax.set_ylabel('Classifier Name', fontweight='bold')
ax.legend(loc=9, bbox_to_anchor=(1.0, 0.75))
plt.show()

Findings:
- We see that the EDA feature subset is far superior to the other feature subsets in terms of not overfitting the training data.
- A bit surprisingly, it is the PCA feature subset that suffers from the worst generalization performance, rather than the full feature set.
We print the pooled test-train absolute accuracy differences below:
print('Pooled Absolute Test-Train Accuracy Difference for...')
print('... Full Feature Set: %.3f %%' % (100.0*diffs_Full_set.mean()))
print('... RFE Feature Subset: %.3f %%' % (100.0*diffs_RFE_set.mean()))
print('... PCA Feature Subset: %.3f %%' % (100.0*diffs_PCA_set.mean()))
print('... EDA Feature Subset: %.3f %%' % (100.0*diffs_EDA_set.mean()))
We see that this difference is almost an order of magnitude smaller for the EDA feature subset compared to the others.
It seems clear that the EDA feature subset is the most promising to continue working with. However, we'll also let the RFE feature set tag along, and see how that does once we've tuned up our classifiers.
4) Model Optimization and Selection¶
Having explored feature importances, our goal now is to obtain an optimized classification algorithm for submitting test-set predictions to Kaggle.
We will begin by optimizing the hyperparameters of our existing classifier set to further improve their performance. For this we'll make use of the cross-validated GridSearch technique that exhaustively checks permutations of specified hyperparameters and identifies the best-performing combinations. We'll then use validation curves for fine-tuning some of these hyperparameters, along with learning curves to verify that our classifiers have maintained good bias-variance tradeoff.
Once our classifiers are tuned up, we'll experiment with different ways of ensembling them, namely through classifier voting and stacking, to obtain a composite classifier whose performance exceeds that of any of its individual constituent classifiers.
4.1 - Exhaustive Hyperparameter Selection with GridSearch¶
Below we define a function that takes a list of classifiers and corresponding 'grids' of hyperparameters to try out, and performs a cross-validated GridSearch to find the parameter combination that yields the highest score for each. (Recall: a hyperparameter is merely a model parameter that is set before training begins.)
def tune_classifier_ensemble(classifiers, param_grids, X_data, y_data,
cv_splits=10, score='accuracy', verbose=True):
"""
Tune classifier hyperparameters using cross-validated GridSearch and return the best results.
: param classifiers : List of classifier objects, assumed to have scikit-learn wrappers.
: param param_grids : List of dictionaries containing the hyperparameters to search over,
matching the list of classifier objects specified in 'classifiers'.
Eah dictionary must have the form {'param_1' : [param_1_value_list],
'param_2' : [param_2_value_list], ... }, where all specified values
must be given as a list, even if single-entried.
: param X_data : Pandas dataframe containing the training feature data.
: param y_data : Pandas dataframe containing the training class labels.
: param cv_splits : Integer number of cross-validation splits.
: param score : String, cross-validated scoring metric, 'accuracy' or 'f1-score'.
: param verbose : Boolean, when true the results are printed for each classifier as they are computed.
: return best_algorithms : A list containing the input classifier objects after fitting on the best
hyperparameter set.
: return best_scores : A list of the best-obtained cross-validated test score for each classifier,
corresponding to the best combination of hyperparameters found.
: return best_parameters : A list of dictionaries containing the best combination of hyperparameters
that yielded the highest cross-validated test score for each classifier.
"""
kfold = StratifiedKFold(n_splits=cv_splits, random_state=27)
best_algorithms = []
best_scores = []
best_parameters = []
total_calc_time = 0.0
for clf, grid in zip(classifiers, param_grids):
start_time = time.time() # for tracking GridSearch execution time
gs = GridSearchCV(estimator=clf, param_grid=grid, cv=kfold, scoring=score, n_jobs=-1)
gs.fit(X_data, y_data)
best_algorithms.append(gs.best_estimator_)
best_scores.append(gs.best_score_)
best_parameters.append(gs.best_params_)
this_calc_time = time.time() - start_time
total_calc_time += this_calc_time
if verbose is True:
print('*** Classifier', len(best_algorithms), 'of', len(classifiers), '***')
print('Classifier Type:', type(best_algorithms[-1]))
print('Best Score: %.4f' % best_scores[-1])
print('Best Parameter Set:', best_parameters[-1])
print('(GridSearch Execution Time: %.2f seconds)' % this_calc_time)
print('\n')
if verbose is True:
print('Total GridSearch Execution Time: %.2f seconds.' % total_calc_time)
return best_algorithms, best_scores, best_parameters
We will begin by using the function we just defined to perform initial hyperparameter tuning on the entire classifier set. Afterwards we will aim to fine-tune each classifier with the help of learning and validation curves.
Below we define our classifiers and the sets of parameter permutations we wish to exhaustively explore with GridSearch:
random_state = 27 # seed for random-number generators, to provide reproducibility
# *** Logistic Regression Classifier ***
lr = LogisticRegression()
lr_param_grid = {'random_state' : [random_state],
'penalty' : ['l2'],
'solver' : ['lbfgs'],
'C' : [0.0001, 0.001, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0]} # regularization strength
# *** Stochastic Gradient Descent with Linear SVC ***
sgd = SGDClassifier()
sgd_param_grid = {'random_state' : [random_state],
'alpha' : [0.0001, 0.001, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0]} # regularization multiplier
# *** Decision Tree Classifier ***
dtc = DecisionTreeClassifier()
dtc_param_grid = {'random_state' : [random_state],
'criterion' : ['gini'],
'max_depth' : [None, 3, 5, 7, 10],
'min_samples_leaf' : [1, 5, 10],
'min_samples_split' : [2, 5, 10],
'max_features': [None, 1, 2, 3, 4]}
# *** ExtraTree Classifier ***
# (highly-randomized version of a Decision Tree)
etc = ExtraTreeClassifier()
etc_param_grid = {'random_state' : [random_state],
'criterion' : ['gini'],
'max_depth' : [None, 3, 5, 7, 10],
'min_samples_leaf' : [1, 5, 10],
'min_samples_split' : [2, 5, 10],
'max_features': [None, 1, 2, 3, 4],
'splitter': ['best', 'random']}
# *** Random Forest Classifier ***
rfc = RandomForestClassifier()
rfc_param_grid = {'random_state' : [random_state],
'criterion' : ['gini'],
'max_features': [None, 2, 3, 4],
'n_estimators': [100, 1000]}
# *** Linear Discriminant Analysis Classifier ***
lda = LinearDiscriminantAnalysis()
lda_param_grid = {'n_components' : [2, 3, 4],
'solver' : ['svd', 'lsqr']}
# *** SVC Classifier (C-Support Vector Classification) ***
svc = SVC()
svc_param_grid = {'random_state' : [random_state],
'C' : [0.5, 1.0, 2.0, 4.0],
'gamma' : ['auto'],
'kernel' : ['rbf', 'linear', 'poly', 'sigmoid'],
'shrinking' : [True, False]}
# *** XGBooster ***
xgb = XGBClassifier()
xgb_param_grid = {'seed' : [random_state],
'booster' : ['gbtree'],
'learning_rate' : [0.05, 0.1, 0.3],
'max_depth' : [3, 6, 10],
'subsample' : [0.2, 0.5, 1.0],
'colsample_bytree' : [0.1, 0.2, 0.5],
'reg_lambda' : [1.0, 1.5, 2.0, 2.5],
'reg_alpha' : [0.0, 0.5, 0.7]}
# *** Gradient Boosting Classifier ***
gbc = GradientBoostingClassifier()
gbc_param_grid = {'random_state' : [random_state],
'loss' : ['deviance'],
'learning_rate': [0.01, 0.05, 0.1],
'n_estimators' : [250, 500],
'max_depth': [3, 6, 9],
'min_samples_leaf': [1, 5],
'max_features': [0.25, 0.50, 0.75, 1.0] # specified here as percentage of max features
}
# *** AdaBoost on a Decision Tree Classifier ***
ada = AdaBoostClassifier(DecisionTreeClassifier())
ada_param_grid = {'random_state' : [random_state],
'base_estimator__criterion' : ['gini'],
'base_estimator__max_depth' : [5],
'base_estimator__min_samples_leaf' : [10],
'base_estimator__min_samples_split' : [2],
'base_estimator__max_features': [2, 3, 4],
'base_estimator__splitter' : ['best'],
'algorithm' : ['SAMME', 'SAMME.R'],
'n_estimators' : [10, 25, 50, 100],
'learning_rate' : [0.01, 0.1, 1.0, 1.5] }
# Assemble classifier and param_grid lists:
classifier_list = [lr,
sgd,
dtc,
etc,
rfc,
lda,
svc,
xgb,
gbc,
ada]
param_grid_list = [lr_param_grid,
sgd_param_grid,
dtc_param_grid,
etc_param_grid,
rfc_param_grid,
lda_param_grid,
svc_param_grid,
xgb_param_grid,
gbc_param_grid,
ada_param_grid]
Next we run the GridSearch, using the EDA feature subset that we identified during Feature Selection in Section 3.6.
best_algorithms, best_scores, best_parameters = tune_classifier_ensemble(classifiers=classifier_list,
param_grids=param_grid_list,
X_data=X_train[feature_subset_EDA],
y_data=y_train)
Comments:
- If we were to repeat this GridSearch hyperparameter optimization using our full feature set and compare it to the above results, we would find that that the EDA feature subset still provides comparable or better performance accuracies, on all classifiers except for RandomForest and LDA; of course, as we found earlier, the EDA feature subset has the superior bias-variance tradeoff.
4.2 - Fine-Tuning Our Classifiers Using Validation Curves¶
Having done a rather 'coarse' hyperparameter sweep during GridSearch, we will now focus on individual hyperparameters to see if fine-tuning can increase performance further. For this we will use validation curves, which display cross-validated test scores for both training and validation data subsets as a function of a swept hyperparameter value.
We will also define a function for checking the bias-variance tradeoff of our tuned classifiers using learning curves, which plot training and test (validation) scores as a function of the number of training samples. Ideally, we'd like to see the train and test scores converge as we increase the size of the training set. Convergence also tells us that we have a sufficient number of training samples for building our model (i.e. that adding additional training samples would not further improve the performance).
def get_validation_curve(classifier, X_data, y_data, param_feed, cv_splits=10,
figure_size=(7, 5), x_scale='linear', y_lim=[0.70, 1.0]):
"""
Generates a validation curve over a specified range of hyperparameter values for a given classifier,
and prints the optimal values yielding i) the highest cross-validated mean accuracy and ii) the smallest
absolute difference between the mean test and train accuracies (to assess overfitting).
: param classifier : Classifier object, assumed to have a scikit-learn wrapper.
: param X_data : Pandas dataframe containing the training feature data.
: param y_data : Pandas dataframe containing the training class labels.
: param param_feed : Dictionary of form {'parameter_name' : parameter_values}, where parameter_values
is a list or numpy 1D-array of parameter values to sweep over.
: param cv_splits : Integer number of cross-validation splits.
: param figure_size : Tuple of form (width, height) specifying figure size.
: param x_scale : String, 'linear' or 'log', controls x-axis scale type of plot.
: param y_lim : List of form [y_min, y_max] for setting the plot y-axis limits.
: return : None.
"""
base_param_name = list(param_feed.keys())[0]
param_range_ = param_feed[base_param_name]
piped_clf = Pipeline([('clf', classifier)]) # I use this merely to assign the handle 'clf' to our classifier
# Obtain the cross-validated scores as a function of hyperparameter value
train_scores, test_scores = validation_curve(estimator=piped_clf,
X=X_train[feature_subset_EDA],
y=y_train,
param_name='clf__' + base_param_name,
param_range=param_range_,
cv=cv_splits)
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
# Generate the validation curve plot
sns.set(font_scale=1.5)
plt.style.use('seaborn-whitegrid')
plt.figure(figsize=figure_size)
plt.plot(param_range_, train_mean, color='blue', marker='o', markersize=5, label='Training Accuracy')
plt.fill_between(param_range_, train_mean + train_std, train_mean - train_std, alpha=0.15, color='blue')
plt.plot(param_range_, test_mean, color='green', linestyle='--', marker='s', markersize=5, label='Validation Accuracy')
plt.fill_between(param_range_, test_mean + test_std, test_mean - test_std, alpha=0.15, color='green')
plt.xscale(x_scale)
plt.xlabel(base_param_name)
plt.ylim(y_lim)
plt.ylabel('Accuracy')
plt.grid(b=True, which='major', color='black', linestyle=':')
plt.legend(loc='lower right')
plt.title('Validation Curve for Parameter ' + base_param_name)
plt.show()
# Display optimal parameter values for best accuracy and smallest train-test difference
diffs = abs(train_mean - test_mean)
id_best_diff = np.argmin(diffs)
id_best_acc = np.argmax(test_mean)
print('Best Accuracy is %.5f occuring at %s = %s' % (test_mean[id_best_acc],
base_param_name,
param_range_[id_best_acc]))
print('Smallest Train-Test Difference is %.5f occuring at %s = %s' % (diffs[id_best_diff],
base_param_name,
param_range_[id_best_diff]))
return
def get_learning_curve(classifier, X_data, y_data, training_sizes=np.linspace(0.1, 1.0, 10), cv_splits=10,
figure_size=(7, 5), y_lim=[0.70, 1.0]):
"""
Generates a learning curve to asses bias-variance tradeoff by plotting cross-validated train and test
accuracies as a function of the number of samples used for training.
: param classifier : Classifier object, assumed to have a scikit-learn wrapper.
: param X_data : Pandas dataframe containing the training feature data.
: param y_data : Pandas dataframe containing the training class labels.
: param training_sizes : Numpy 1D array of the training sizes to sweep over, specified as fractions
of the total training set size.
: param cv_splits : Integer number of cross-validation splits.
: param figure_size : Tuple of form (width, height) specifying figure size.
: param y_lim : List of form [y_min, y_max] for setting the plot y-axis limits.
: return : None.
"""
# Obtain the cross-validated scores as a function of the training size
train_sizes, train_scores, test_scores = learning_curve(estimator=classifier,
X=X_data,
y=y_data,
train_sizes=training_sizes,
cv=cv_splits,
n_jobs=-1)
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
# Generate the learning curve plot
sns.set(font_scale=1.5)
plt.style.use('seaborn-whitegrid')
plt.figure(figsize=figure_size)
plt.plot(train_sizes, train_mean, color='blue', marker='o', markersize=5, label='Training Accuracy')
plt.fill_between(train_sizes, train_mean + train_std, train_mean - train_std, alpha=0.15, color='blue')
plt.plot(train_sizes, test_mean, color='red', linestyle='--', marker='s', markersize=5, label='Validation Accuracy')
plt.fill_between(train_sizes, test_mean + test_std, test_mean - test_std, alpha=0.15, color='red')
plt.xlabel('Number of Training Samples')
plt.ylim(y_lim)
plt.ylabel('Accuracy')
plt.grid(b=True, which='major', color='black', linestyle=':')
plt.legend(loc=4)
plt.title('Learning Curve')
plt.show()
return
I have explored fine-tuning for each of our classifiers, and in most cases we were already at the optimum, so below I highlight only the cases where this leads to a non-trivial improvement.
Fine-Tuning the SGD Classifier:¶
Results from our GridSearch:
- Best Score: 0.7969
- Best Parameter Set: {'alpha': 0.1}
First we can try fine-tuning alpha in the vicinity of 0.1. Alpha is the constant multiplying the regularization term.
alpha_feed = np.arange(0.01, 0.2, 0.005)
get_validation_curve(best_algorithms[1], X_data=X_train[feature_subset_EDA], y_data=y_train,
param_feed={'alpha' : alpha_feed},
cv_splits=10, figure_size=(7, 5), x_scale='linear', y_lim=[0.75, 0.82])

So it appears we can do a little better in accuracy. Let's set alpha=0.12, where we have higher accuracy and little difference between the training and validation accuracies, while giving us some buffer before things drop off near alpha=0.13 where there might be some instability.
best_algorithms[1].set_params(**{'alpha': 0.12, 'n_jobs': -1})
We can also try changing the loss scheme to from 'hinge' to 'huber' and tune epsilon (which determines the threshold at which it becomes less important to get the prediction exactly right):
best_algorithms[1].set_params(**{'loss': 'huber'})
epsilon_feed = np.linspace(0.25, 2.5, 50)
get_validation_curve(best_algorithms[1], X_data=X_train[feature_subset_EDA], y_data=y_train,
param_feed={'epsilon' : epsilon_feed},
cv_splits=10, figure_size=(7, 5), x_scale='linear', y_lim=[0.75, 0.82])

Using the 'huber' loss method results in a higher accuracy, and a good setting for epsilon where we achieve high accuracy but also some stability is epsilon=2.0. So let's update our classifier parameters accordingly:
best_algorithms[1].set_params(**{'epsilon': 2.0})
Finally, let's assess the bias-variance tradeoff by plotting a learning curve for this classifier:
get_learning_curve(best_algorithms[1], X_data=X_train[feature_subset_EDA], y_data=y_train,
cv_splits=10, figure_size=(7, 5), y_lim=[0.75, 0.85])

With our current parameter set, the training and validation accuracies appear to converge. The rate of convergence for this SGD classifier is remarkably fast compared to what we might typically expect. Perhaps this is due to the simplicity of our model?
Fine-Tuning the Decision Tree Classifier:¶
Results from our GridSearch:
- Best Score: 0.8328
- Best Parameter Set: {'criterion': 'gini', 'max_depth': 5, 'max_features': 2, 'min_samples_leaf': 5, 'min_samples_split': 2}
We can gain a slight accuracy increase if we tune over min_samples_leaf:
min_samples_leaf_feed = [2, 3, 4, 5, 6, 7, 8, 9, 10]
get_validation_curve(best_algorithms[2], X_data=X_train[feature_subset_EDA], y_data=y_train,
param_feed={'min_samples_leaf' : min_samples_leaf_feed},
cv_splits=10, figure_size=(7, 5), x_scale='linear', y_lim=[0.75, 0.85])

We find that min_samples_leaf=6 is slightly better than our previous setting, so let's update our parameters:
best_algorithms[2].set_params(**{'min_samples_leaf' : 6})
Next we'll view the learning curve:
get_learning_curve(best_algorithms[2], X_data=X_train[feature_subset_EDA], y_data=y_train,
cv_splits=10, figure_size=(7, 5), y_lim=[0.75, 0.85])

We obtain good training/validation convergence at 800 training samples.
Fine-Tuning the RandomForest Classifier:¶
Results from our GridSearch:
- Best Score: 0.8238
- Best Parameter Set: {'criterion': 'gini', 'max_features': None, 'n_estimators': 100}
We'll try tuning the parameter min_samples_split, which defaults to a value of 2 (see documentation):
min_samples_split_feed = [2, 4, 6, 8, 10, 12, 14, 16]
get_validation_curve(best_algorithms[4], X_data=X_train[feature_subset_EDA], y_data=y_train,
param_feed={'min_samples_split' : min_samples_split_feed},
cv_splits=10, figure_size=(7, 5), x_scale='linear', y_lim=[0.75, 0.85])

Validation accuracy goes up and bias-variance tradeoff improves at min_samples_split = 10. That's great! Let's update our params:
best_algorithms[4].set_params(**{'min_samples_split' : 10})
If we try increasing the number of estimators, we don't find any further improvement. So finally, let's check the learning curve:
get_learning_curve(best_algorithms[4], X_data=X_train[feature_subset_EDA], y_data=y_train,
cv_splits=10, figure_size=(7, 5), y_lim=[0.75, 0.90])

The convergence reassures us of good bias-variance tradeoff.
4.3 - The Impact of Excluding the Guarantee Group¶
What training data we provide can also be considered a hyperparameter (e.g. our choice of features). Earlier, when investigating fare outliers in Section 2.2, we discovered that several of our passengers were actually employees (the so-called 'Guarantee Group') from the shipbuilding company who were travelling with the Titanic on its maiden voyage to help ensure smooth operation and spot any necessary improvements. Irrespective of class, virtually all of this Guarantee Group perished. We hypothesized, these being employees, that their survival might belong to a model different from that of our non-employee passengers, and hence we considered excluding them from our training data.
Here, using our tuned-up classifiers, we investigate explicitly the impact of dropping the Guarantee Group from our training data.
# obtain the dataframe indexes of the Guarantee Group passengers
gg_indexes = data_train_cl_std.index[data_train_cl_std['IsGG'] == 1].tolist()
# obtain scores for our recently-optimized classifier set before dropping GG members
comp_GG_kept, _ = train_classifier_ensemble_CV(classifiers=best_algorithms,
X_data=X_train[feature_subset_EDA],
y_data=y_train)
# obtain scores for our recently-optimized classifier set after dropping GG members
comp_GG_dropped, _ = train_classifier_ensemble_CV(classifiers=best_algorithms,
X_data=X_train[feature_subset_EDA].drop(gg_indexes),
y_data=y_train.drop(gg_indexes))
# create a dataframe for comparison
comp_GG_impact = pd.DataFrame(columns=['Classifier Name', 'Change To Accuracy'])
comp_GG_impact['Classifier Name'] = comp_GG_kept['Classifier Name']
comp_GG_impact['Change To Accuracy'] = (comp_GG_dropped['Mean Test Accuracy'] - comp_GG_kept['Mean Test Accuracy'])
# display results
comp_GG_impact
Findings:
- The change to accuracy is nearly negligible, which perhaps is not so surprising given that the Guarantee Group represents such a small fraction of our total training set, and belonged to the sex that was most likely to perish anyways.
- There is nonetheless a small decrease in cross-validated accuracy, most pronounced for the SGD classifier. So we will choose to keep the Guarantee Group in our dataset after all. If we chose to, we could also invest some time to explore the impact on the test-train differences, but we'll presume that the model generalization, being already so good even with the Guarantee Group included, is not going to be much affected by their removal.
4.4 - Ensemble Voting¶
Ensemble techniques allow us to draw from the strengths of each of our classifiers while mitigating their weaknesses. One such approach is through classifier voting, where the final prediction is decided by either a majority vote or a weighted vote of the predictions made by each constituent classifier.
The benefits of voting are as follows. In a decision region where one particular classification algorithm does poorly compared to the others, its incorrect predictions can be overruled by other classifiers. In this way we help to consolidate our accuracy. Whatsmore, under the ideal assumptions of independent classifiers having equal error rates (that are less than 50%), it can be mathematically proven that pooling these classifier results into a vote reduces the overall error rate. Of course, while we don't necessarily meet these assumptions, it's worth exploring whether ensemble voting can offer us any improvements.
Building our Voting Classifier¶
We'll start by assembling all of the classifier algorithms we optimized during hyperparameter tuning, and pooling these through majority voting. We'll print the cross-validated accuracy of each individual classifier, followed by that of the voting classifier.
estimator_ensemble = [('lr', best_algorithms[0]),
('sgd', best_algorithms[1]),
('dtc', best_algorithms[2]),
('etc', best_algorithms[3]),
('rfc', best_algorithms[4]),
('lda', best_algorithms[5]),
('svc', best_algorithms[6]),
('xgb', best_algorithms[7]),
('gbc', best_algorithms[8]),
('ada', best_algorithms[9])]
kfold = StratifiedKFold(n_splits=10, random_state=27)
# get accuracies of our individual trained classifiers for comparison
estimators = [estimator_ensemble[i][1] for i in range(len(estimator_ensemble))]
clf_names = [get_clf_name(clf) for clf in estimators]
for clf, clf_name in zip(estimators, clf_names):
scores = cross_val_score(clf, X=X_train[feature_subset_EDA], y=y_train, cv=kfold, scoring='accuracy')
print("Accuracy: %0.4f (+/- %0.4f) [%s]" % (scores.mean(), scores.std(), clf_name))
# fit and score the majority vote classifier on our entire classifier ensemble
mvc = VotingClassifier(estimators=estimator_ensemble, voting='hard', weights=None, n_jobs=-1, flatten_transform=None)
scores = cross_val_score(estimator=mvc, X=X_train[feature_subset_EDA], y=y_train, cv=kfold, scoring='accuracy')
print("Accuracy: %0.4f (+/- %0.4f) [%s]" % (scores.mean(), scores.std(), get_clf_name(mvc)))
Our voting classifier does not appear to be offering any overall accuracy improvement. A few possible reasons for this are:
- Its constituent classifiers are too highly correlated, and therefore not very 'independent' (so we're not getting the full mathematical benefit of voting).
- The SGD and Logistic Regression classifiers are roughly 2% less accurate than the other classifiers, yet their votes are weighted the same as those of other classifiers.
Reducing the Number of Classifiers¶
The first thing we can try is reducing the number of classifiers, choosing those that tend to be more 'independent' (i.e. whose predictions are not as highly correlated with one-another). We will retrieve our training set predictions for each classifier, obtain their Pearson correlation coefficients, and display these in a heatmap:
# obtain class predictions
train_probas = [clf.fit(X_train[feature_subset_EDA], y_train).predict(X_train[feature_subset_EDA])
for clf in estimators]
# format into pandas dataframe
df_train_probas = pd.DataFrame(columns=clf_names)
for name, probas in zip(clf_names, train_probas):
df_train_probas[name] = probas
# generate correlation matrix
plt.figure(figsize=(12,12))
sns.set(font_scale=1.5)
g = sns.heatmap(df_train_probas.corr(), square=True, annot=True, cmap='coolwarm', fmt='.2f')

Findings:
- The SVC, XGB, Gradient Boosting, AdaBoost, ExtraTree, and Decision Tree classifiers all appear strongly correlated with one another. Let's omit half of these classifiers, keeping the three with the highest accuracy scores (ExtraTree, XGB, AdaBoost).
- The Logistic Regression, LDA, and SGD classifiers were also strongly correlated with each other. Of these, Logistic Regression had the best performance, so we'll drop the other two.
Let's now see if our voting classifier improves:
estimator_ensemble = [('lr', best_algorithms[0]),
('etc', best_algorithms[3]),
('rfc', best_algorithms[4]),
('xgb', best_algorithms[7]),
('ada', best_algorithms[9])]
kfold = StratifiedKFold(n_splits=10, random_state=27)
# get accuracies of our individual trained classifiers for comparison
estimators = [estimator_ensemble[i][1] for i in range(len(estimator_ensemble))]
clf_names = [get_clf_name(clf) for clf in estimators]
for clf, clf_name in zip(estimators, clf_names):
scores = cross_val_score(clf, X=X_train[feature_subset_EDA], y=y_train, cv=kfold, scoring='accuracy')
print("Accuracy: %0.4f (+/- %0.4f) [%s]" % (scores.mean(), scores.std(), clf_name))
# fit and score the majority vote classifier on our entire classifier ensemble
mvc = VotingClassifier(estimators=estimator_ensemble, voting='hard', weights=None, n_jobs=-1, flatten_transform=None)
scores = cross_val_score(estimator=mvc, X=X_train[feature_subset_EDA], y=y_train, cv=kfold, scoring='accuracy')
print("Accuracy: %0.4f (+/- %0.4f) [%s]" % (scores.mean(), scores.std(), get_clf_name(mvc)))
Somewhat surprisingly, we don't see an improvement. Experimenting with soft voting and weight adjustment also yields no further improvement. This could in part be due to the simplicity of our model. While voting here does not appear to improve our accuracy, it might nonetheless be desirable to use this voting classifier for predictions on unseen data, as the pooling of classifiers still offers greater robustness.
Finally, let's view the learning curve for our majority vote classifier:
get_learning_curve(mvc, X_data=X_train[feature_subset_EDA], y_data=y_train,
cv_splits=10, figure_size=(7, 5), y_lim=[0.75, 0.90])

4.5 - Ensemble Stacking¶
Stacking is a much more versatile way of combining classifier results. It involves the creation of an additional classifier layer that takes the predictions of the base classifiers as its input ("meta-features") for training. In this way, the 2nd-level classifier can learn the relative strengths and weaknesses of its base classifiers to make a smarter decision about how to weigh their predictions. This powerful technique has emerged as one of the most effective approaches to many classification tasks and nowadays is ubiquitous in top-performing Kaggle entries. It's a deep and diverse topic in its own right, but here we'll just cover the basics. For more details on this topic, I'd recommend checking out the work of prominent Kaggler Alexander Guschin.
Adding KNN to Diversify our Ensemble¶
An important part of stacking is choosing combinations of base classifiers that complement each other. Some classifiers will be better at handling certain parts of the decision region than others.
Anecdotal evidence suggests that the K-Nearest Neighbors classifier would be a good one to add to our existing ensemble, so let's define it below. I'll initialize it with an optimized set of hyperparameters found during a separate GridSearch.
knn = KNeighborsClassifier(n_neighbors=8,
weights='uniform',
algorithm='auto',
leaf_size=15,
p=2,
metric='minkowski',
metric_params=None,
n_jobs=-1)
scores = cross_val_score(estimator=knn, X=X_train[feature_subset_EDA], y=y_train, cv=kfold, scoring='accuracy')
print("Accuracy: %0.4f (+/- %0.4f) [%s]" % (scores.mean(), scores.std(), get_clf_name(knn)))
Building Our Stacked Ensemble¶
I'll choose to train our 2nd-level classifier using 'out-of-fold' predictions from the base classifier set. The procedure is as follows:
- Split the training dataset into n folds.
- For each of these folds, use one as a 'validation set' while training the base classifiers on all the others. Then obtain predictions on the 'validation set'.
- After repeating step 2 for all folds, combine the 'validation set' predictions. These are our 'out-of-fold' predictions; each of these predictions were made by classifiers that hadn't seen that particular sample before.
- Use these out-of-fold predictions for each classifier as the input training features for our 2nd-level classifer.
Below I define a function for obtaining the out-of-fold predictions for a set of input classifiers:
def get_oof_predictions(classifiers, X_data, y_data, cv_splits=5, random_state=27):
"""
Returns out-of-fold predictions, as a pandas dataframe, for the input list of classifiers.
"""
clf_names = [get_clf_name(clf) for clf in classifiers]
oof_preds = pd.DataFrame(columns=clf_names)
kfold = StratifiedKFold(n_splits=cv_splits, random_state=random_state)
for i, clf in enumerate(classifiers):
this_clf_oof_preds = y_data.copy() # entries will be overwritten
for (train, test) in kfold.split(X_data, y_data):
clf.fit(X_data.iloc[train], y_data.iloc[train])
this_clf_oof_preds.iloc[test] = clf.predict(X_data.iloc[test])
oof_preds[clf_names[i]] = this_clf_oof_preds
return oof_preds
Now it comes to the decision about which classifiers to include. As before, it's best to pick classifiers that are not as strongly correlated with one another. We've chosen classifiers based on the heatmap in Section 4.5, have added the KNN classifier, and have found the optimal set based on some trial and error. We obtain the out-of-fold (OOF) predictions for these below:
estimator_ensemble = [best_algorithms[0],
best_algorithms[4],
best_algorithms[7],
best_algorithms[9],
knn]
oof_preds = get_oof_predictions(classifiers=estimator_ensemble,
X_data=X_train[feature_subset_EDA],
y_data=y_train)
oof_preds.head(5)
For our 2nd-level classifier, we'll use the popular XGB technique with a logistic objective function:
level2_xgb = XGBClassifier(seed=random_state, nthread=-1, objective='binary:logistic', n_estimators=1000)
kfold = StratifiedKFold(n_splits=10, random_state=27)
scores = cross_val_score(estimator=level2_xgb, X=oof_preds, y=y_train, cv=kfold, scoring='accuracy')
print("Accuracy: %0.4f (+/- %0.4f) [%s]" % (scores.mean(), scores.std(),
'Stacking with ' + get_clf_name(level2_xgb)))
Findings:
- We've managed to obtain a small (0.2%) accuracy improvement over the individual base classifiers.
Let's also double-check the generalization performance with a learning curve:
get_learning_curve(level2_xgb, X_data=oof_preds, y_data=y_train,
cv_splits=10, figure_size=(7, 5), y_lim=[0.75, 0.90])

The learning curve tells us that we are still achieving good generalization.
4.6 - Further Improvements¶
The model we have developed here was ultimately based on a simple set of features whose selection was informed by our Exploratory Data Analysis. These features were Sex, Pclass, AgeBin, and LargeGroup. Our final cross-validated accuracy (83.84% using our Stacking method) is reasonably high, and we've taken care to ensure good generalization performance, which is likely critical for obtaining a good score on the unseen test data.
On the other hand, our training and validation accuracies converge surprisingly quickly even at a low number of samples, perhaps indicating our model is too simple (e.g. validation accuracy is already at 83% for 100 samples). There is also a very large standard deviation on our validation accuracy.
I suspect there are three more features we could consider including that might further enhance performance. In Section 1.4.i) we considered the question of whether groups of co-travellers tended to perish or survive together. In particular, the feature 'GroupNumSurvived', which tells us how many others in a passenger's ticket group are known to have survived (from the training set), combined with 'GroupSize', could be useful. 'GroupType' might also complement these two. It would be interesting to add these features to our models, re-optimize, and see if it improves our accuracy.
4.7 - Preparing our Prediction Submission¶
The Kaggle submission file needs to be a CSV with one header row and only two columns, specifying 'PassengerID' and the predicted value of 'Survived' for the test set. We prepare this submission file below:
# create a dataframe for our prediction submission
survival_predictions = pd.DataFrame(columns=['PassengerId', 'Survived'])
survival_predictions['PassengerId'] = ids_test
# ensure our stacked classifier is fit on our oof training set predictions
level2_xgb.fit(oof_preds, y_train)
# train our estimator ensemble on the entire training set and get classifier predictions
# on our test set to create meta-features for level2_xgb
clf_names = [get_clf_name(clf) for clf in estimator_ensemble]
X_test_meta = pd.DataFrame(columns=clf_names) # specify columns upfront so we fix their order
for i, clf in enumerate(estimator_ensemble):
clf.fit(X_train[feature_subset_EDA], y_train)
X_test_meta[clf_names[i]] = clf.predict(X_test[feature_subset_EDA])
# obtain predictions from our stacked classifier
survival_predictions['Survived'] = level2_xgb.predict(X_test_meta)
# save results to CSV file (dropping the index column)
survival_predictions.to_csv('./titanic-data/prediction_submission_1.csv', index=False, float_format='%.f')